Market Definition
Synthetic data is artificial data designed to mimic real-world data. It is artificially generated but retains the statistical properties of the original data from which it was generated. Synthetic data generation can happen in tabular, multimedia, or text form. Synthetic text data can be useful for natural language processing (NLP). Similarly, tabular data has applications in the creation of relational database tables.
Synthetic multimedia includes images, videos, and other unstructured data, which can be crucial for computer vision tasks such as image recognition and image classification, among others. There are growing data requirements in sectors like finance, healthcare, and retail. Synthetic data is helping such organizations by accelerating AI innovation and enabling smarter decisions.
Synthetic Data Generation Market Overview
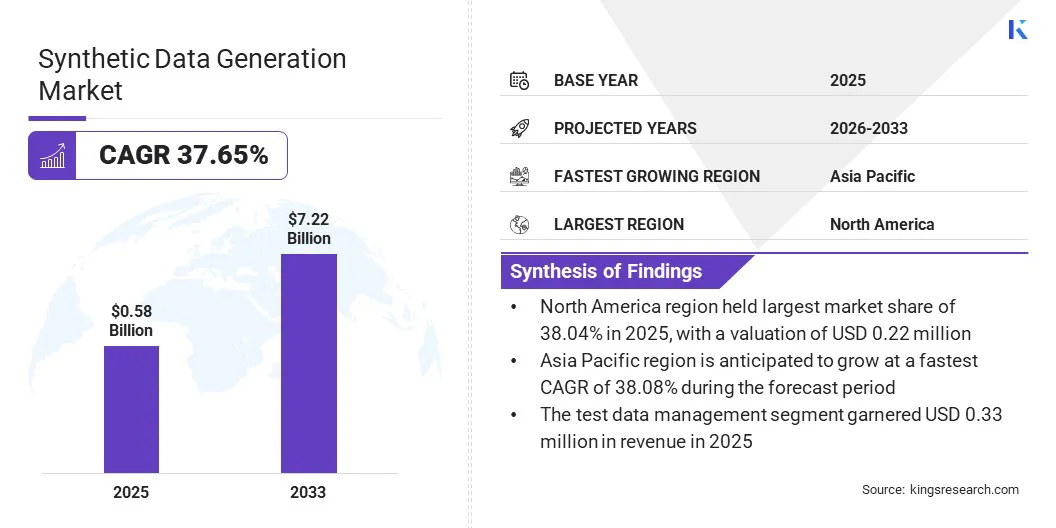
The global synthetic data generation market size was valued at USD .58 billion in 2025 and is projected to grow from USD .77 billion in 2026 to USD 7.22 billion by 2033, exhibiting a CAGR of 37.65% during the forecast period. This growth is attributed to its application for test systems, training AI models, and simulating scenarios, which is generally difficult to capture in real data.
For instance, in the healthcare sector, synthetic medical records can signify conditions such as diabetes, disease, or cancer, which can help to develop and test diagnostic tools along with predictive health models.
Major companies operating in the global synthetic data generation market are MOSTLY AI, Datagen, TonicAI, Inc., GenRocket, Inc, NVIDIA (Gretel Labs), K2view Ltd, CapGemini (Sogeti), CVEDIA Inc, Microsoft Corporation, and MDClone among others.
Synthetic data demand is expected to grow with its growing use in several sectors, including the automotive sector for the testing of autonomous vehicles, healthcare for medical imaging analysis, and patient diagnosis. In the retail sector, it is largely used for investment management and customer behavior analysis.
It can be beneficial in finance for fraud detection and risk assessment. The key advantage of synthetic data comprises cost-effectiveness, scalability, and diversity. These are largely used in training machine learning models. It offers greater control over data quality and also preserves privacy by eliminating the use of the real, sensitive data.
The recent trend indicates the integration of federated learning and differential privacy for enhancing the privacy preserving machine learning. Also, the demand for diverse and high-quality training datasets will grow with the expansion of AI in new domains, making synthetic data very crucial.
Key Highlights:
- The global synthetic data generation market size was recorded at USD .58 billion in 2025.
- The market is projected to grow at a CAGR of 37.65% from 2026 to 2033.
- North America held a share of 38.04% in 2025, valued at USD .22 billion.
- The tabular data segment garnered USD .20 billion in revenue in 2025.
- The test data management segment is expected to reach USD 4.05 billion by 2033.
- The healthcare segment is anticipated to witness the fastest CAGR of 38.28% over the forecast period.
- Asia Pacific is anticipated to grow at a CAGR of 38.08% through the projection period.
How dependable is synthetic data for AI training?
Synthetic data, when generated using robust techniques, can match or, in some cases, outperform the real data in model performance, particularly in rare-event scenarios.
While it cannot replace the real data, it is very effective when supporting the real data, particularly when team deals with limited data, unbalanced data sets, or privacy constraints. As a result, it can work as a powerful complement to real data rather than a complete replacement.
- In October 2024, MOSTLY AI revealed its new synthetic text functionality for training AI models, and it also takes care of the privacy of proprietary data assets. It helps the organization to use a broad range of text data such as emails, chatbot conversations, customer support transcripts, etc., for training and fine-tuning the large language models (LLMs), and there is no risk of privacy breach.
Why training of AI systems requires the awareness that synthetic data can create false results?
Synthetic data may lack the complexity and nuances of real-world data, which can cause AI models to perform poorly in real-world scenarios. Moreover, there is a possibility that AI models that are completely trained on synthetic data could not generalize effectively to real-world situations because of disparities between synthetic and actual data. It could also raise ethical concerns in some of the applications, such as medical diagnosis.
How does synthetic data generation offer business advantages in terms of cost and scalability?
Real data collection is costly and slow with the association of sensor deployment, labelling, and security. But the synthetic data for online machine learning can be easily generated more cheaply and faster. Synthetic data offers controlled and scalable data sources for robust development of AI. For instance, organizations such as Nvidia and Databricks offer tools such as Unity Catalog and Omniverse Replicator for automating synthetic data pipelines. There is an estimation that around 50% to 60% of the data used for training AI platforms is synthetic. Its demand is increasing as it helps organizations to simulate new products, accelerate AI model development, and protect sensitive information.
- In October 2025, GenRocket announced the launch of its Unstructured Data Accelerator (UDA), which has led the design-driven synthetic data generation organization to expand its platform beyond structured data to images, documents and file-based formats. It has helped the organization in generating any form of data safely, precisely, and at scale on demand.
Synthetic Data Generation Market Report Snapshot
|
Segmentation
|
Details
|
|
By Data
|
Tabular Data, Text Data, Image & Video Data, Others
|
|
By Application
|
Test Data Management, AI training and Development, Enterprise Data Sharing, Data Analytics & Visualization
|
|
By End user
|
Financial Services, Retail, Healthcare and Others
|
|
By Region
|
North America: U.S., Canada, Mexico
|
|
Europe: France, UK, Spain, Germany, Italy, Russia, Rest of Europe
|
|
Asia-Pacific: China, Japan, India, Australia, ASEAN, South Korea, Rest of Asia-Pacific
|
|
Middle East & Africa: Turkey, U.A.E., Saudi Arabia, South Africa, Rest of Middle East & Africa
|
|
South America: Brazil, Argentina, Rest of South America
|
Market Segmentation
- By Data (Tabular Data, Text Data, Image & Video Data, and Others): The tabular data segment generated USD .20 billion in revenue in 2025, mainly due to its growing adoption in the e-commerce and healthcare sectors. It is largely used for training some machine learning models effectively.
- By Application (Test Data Management, AI training and Development, Enterprise Data Sharing, and Data Analytics & Visualization): The AI training and development segment is poised to record a staggering CAGR of 38.08% through the forecast period, propelled by its broad requirement in training machine learning models. It is serving as a potential solution for scenarios where there is a requirement for data, but there is a short supply of high-quality real-world data for training AI models.
- By End User (Financial Services, Retail, Healthcare, and Others): The financial services segment is estimated to hold a share of 32.13% by 2032, fueled by the synthetic data’s advantages like safe data sharing and model development for risk assessment, fraud detection, and analytics without exposing the real client information. Synthetic data generation can be possible for rare events such as market crashes or complex fraud forms, which help in improving the model performance and speeding up the AI development.
What is the market scenario in North America and the Asia Pacific region?
Based on region, the global synthetic data generation market has been classified into North America, Europe, Asia Pacific, Middle East & Africa, and South America.

The North America synthetic data generation market accounted for a share of 38.04% in 2025, valued at USD .22 billion. This dominance is attributed to a combination of advanced technological infrastructure and more investment in R&D in the region. In the U.S., in particular, businesses are adopting latest technologies to decrease the risks and inefficiency.
Moreover, consumers prefer to support brands that focus on incremental innovations. In retail, synthetic data generation is helping in analyzing customer preference such as shopping habits and seasonal demand, while protecting privacy at the same time. The region has growing data privacy obligations and a strong AI ecosystem, which is creating a favorable environment for the market to grow.
- In June 2021, CVEDIA announced a solution for the domain adoption gap using the proprietary synthetic data pipeline. They can help in the development of AI by enabling algorithms trained on synthetic data to perform along with those trained on real data. CVEDIA claimed the precision improvement of 170% and sustained a gain of 160% in recall compared with benchmark models.
The Asia-Pacific synthetic data generation market is set to grow at a CAGR of 38.08% over the forecast period. This notable growth is supported by the growing use of synthetic data in several domains in the region, such as healthcare, manufacturing, etc.
For instance, in healthcare, the synthetic data is generated for creating realistic patient records, which help research while offering anonymization and aggregation. It helps medical researchers in developing and testing algorithms for diagnosis and treatment while following the strict data protection regulations.
In manufacturing, the auto companies are using synthetic data to simulate a number of driving scenarios for the autonomous cars. It helps in training machine learning models for recognizing and responding to several conditions without the requirement for extensive real-world data collection. Companies such as Waymo and Tesla are revolutionizing the use of synthetic data for training their self-driving cars.
Regulatory Frameworks
- The General Data Protection Regulation (GDPR) has control over the processing of personal data in the EU, and it defines what qualifies as anonymized or synthetic data.
- The Data (Use and Access) Act 2025 in the UK takes care of the provisions related to the processing and access of personal and business data. It updates the existing UK GDPR and Data Protection Act framework.
- In the United States (California), the California Consumer Privacy Act (CCPA) and its amendment, the California Privacy Rights Act (CPRA) govern the collection and use of personal data.
Competitive Landscape
Key players in the synthetic data generation market are largely focusing on continuous technological innovation. There are many small players and mid-sized players that are targeting particular data types and sectors. The specialist vendors are not holding a dominant market share and are operating in niche segments.
Big cloud and AI platforms, such as Microsoft and NVIDIA, among others having a key portion in the market as synthetic data capabilities are present within broader AI and ML services. Focus is also on partnerships and acquisitions for strategic advantages.
- In March 2025, Nvidia acquired Gretel, a synthetic data startup, for more than USD 320 million, which is helping its suite of generative AI services for developers. Gretel maintains partnerships with major cloud providers such as Google Cloud, Amazon Web Services, and Microsoft.
Key Companies in Synthetic Data Generation Market:
Recent Developments (Partnerships)
- In April 2023, MDClone announced that its ADAMS platform is enabling more number of partnerships between healthcare provider organizations and life sciences companies for speeding up the therapeutic research and development.


