Tamaño del mercado de generación de datos sintéticos, participación, crecimiento y análisis de la industria, por datos (datos tabulares, datos de texto, datos de imágenes y videos, otros), por aplicación (gestión de datos de prueba, capacitación y desarrollo de inteligencia artificial, intercambio de datos empresariales, análisis y visualización de datos), por usuario final (servicios financieros, comercio minorista, atención médica, otros) y análisis regional. 2026-2033
Páginas: 180 | Año base: 2025 | Lanzamiento: febrero de 2026 | Autor: Ashim L. | Última actualización: marzo de 2026
Los datos sintéticos son datos artificiales diseñados para imitar datos del mundo real. Se genera artificialmente pero conserva las propiedades estadísticas de los datos originales a partir de los cuales se generó. La generación de datos sintéticos puede ocurrir en forma tabular, multimedia o de texto. Los datos de texto sintéticos pueden resultar útiles para el procesamiento del lenguaje natural (PLN). De manera similar, los datos tabulares tienen aplicaciones en la creación de tablas de bases de datos relacionales.
Los multimedia sintéticos incluyen imágenes, vídeos y otros datos no estructurados, que pueden ser cruciales para tareas de visión por computadora como el reconocimiento y la clasificación de imágenes, entre otras. Existen crecientes necesidades de datos en sectores como las finanzas, la atención sanitaria y el comercio minorista. Los datos sintéticos están ayudando a estas organizaciones al acelerar la innovación en IA y permitir decisiones más inteligentes.
Mercado de generación de datos sintéticosDescripción general
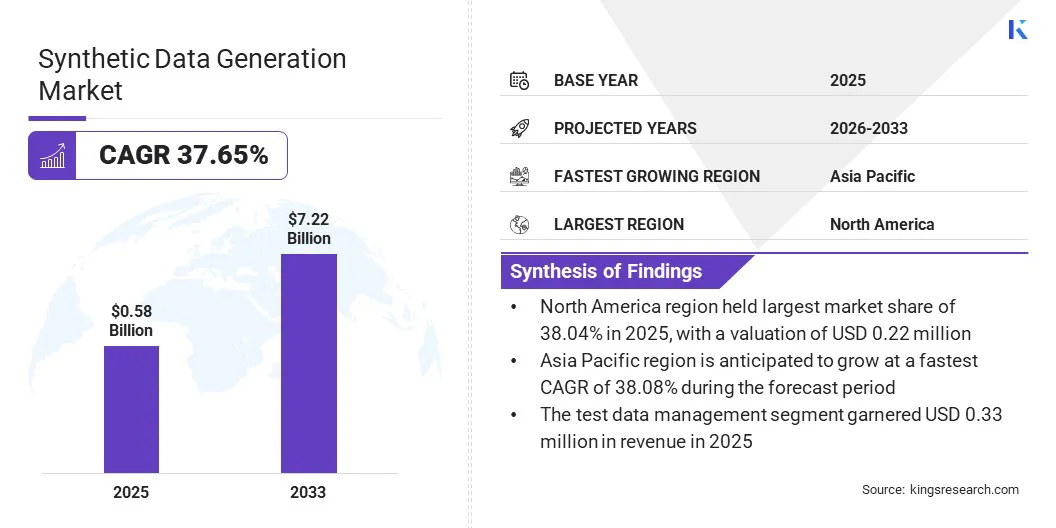
El tamaño del mercado mundial de generación de datos sintéticos se valoró en 580 millones de dólares en 2025 y se prevé que crezca de 770 millones de dólares en 2026 a 7220 millones de dólares en 2033, exhibiendo una tasa compuesta anual del 37,65% durante el período previsto. Este crecimiento se atribuye a su aplicación para sistemas de prueba, entrenamiento de modelos de IA y simulación de escenarios, que generalmente es difícil de capturar en datos reales.
Por ejemplo, en el sector de la salud, los registros médicos sintéticos pueden indicar afecciones como diabetes, enfermedades o cáncer, lo que puede ayudar a desarrollar y probar herramientas de diagnóstico junto con modelos de salud predictivos.
Las principales empresas que operan en el mercado global de generación de datos sintéticos son MOSTLY AI, Datagen, TonicAI, Inc., GenRocket, Inc, NVIDIA (Gretel Labs), K2view Ltd, CapGemini (Sogeti), CVEDIA Inc, Microsoft Corporation y MDClone, entre otras.
Se espera que la demanda de datos sintéticos crezca con su creciente uso en varios sectores, incluido el sector automotriz para las pruebas devehículos autónomos, atención médica para análisis de imágenes médicas y diagnóstico de pacientes. En el sector minorista, se utiliza principalmente para la gestión de inversiones y el análisis del comportamiento del cliente.
Puede resultar beneficioso en finanzas para la detección de fraudes y la evaluación de riesgos. La ventaja clave de los datos sintéticos comprende la rentabilidad, la escalabilidad y la diversidad. Estos se utilizan principalmente en el entrenamiento de modelos de aprendizaje automático. Ofrece un mayor control sobre la calidad de los datos y también preserva la privacidad al eliminar el uso de datos reales y confidenciales.
La tendencia reciente indica la integración del aprendizaje federado y la privacidad diferencial para mejorar la privacidad y preservar el aprendizaje automático. Además, la demanda de conjuntos de datos de entrenamiento diversos y de alta calidad crecerá con la expansión de la IA en nuevos dominios, lo que hará que los datos sintéticos sean muy cruciales.
Aspectos destacados clave:
El tamaño del mercado mundial de generación de datos sintéticos se registró en 580 millones de dólares en 2025.
Se prevé que el mercado crezca a una tasa compuesta anual del 37,65% entre 2026 y 2033.
América del Norte tuvo una participación del 38,04% en 2025, valorada en 220 millones de dólares.
El segmento de datos tabulares obtuvo 200 millones de dólares de ingresos en 2025.
Se espera que el segmento de gestión de datos de prueba alcance los 4.050 millones de dólares en 2033.
Se prevé que el segmento de atención médica sea testigo del CAGR más rápido del 38,28% durante el período previsto.
Se prevé que Asia Pacífico crezca a una tasa compuesta anual del 38,08% durante el período de proyección.
¿Qué tan confiables son los datos sintéticos para el entrenamiento de IA?
Los datos sintéticos, cuando se generan utilizando técnicas sólidas, pueden igualar o, en algunos casos, superar a los datos reales en el rendimiento del modelo, particularmente en escenarios de eventos raros.
Si bien no puede reemplazar los datos reales, es muy eficaz cuando respalda los datos reales, especialmente cuando el equipo maneja datos limitados, conjuntos de datos desequilibrados o restricciones de privacidad. Como resultado, puede funcionar como un poderoso complemento de los datos reales en lugar de un reemplazo completo.
En octubre de 2024, MOSTLY AI reveló su nueva funcionalidad de texto sintético para entrenar modelos de IA y también se ocupa de la privacidad de los activos de datos propietarios. Ayuda a la organización a utilizar una amplia gama de datos de texto, como correos electrónicos, conversaciones de chatbot, transcripciones de atención al cliente, etc., para capacitar y perfeccionar elmodelos de lenguaje grandes (LLM)y no hay riesgo de violación de la privacidad.
¿Por qué el entrenamiento de sistemas de IA requiere ser consciente de que los datos sintéticos pueden generar resultados falsos?
Los datos sintéticos pueden carecer de la complejidad y los matices de los datos del mundo real, lo que puede hacer que los modelos de IA funcionen mal en escenarios del mundo real. Además, existe la posibilidad de que los modelos de IA que están completamente entrenados con datos sintéticos no puedan generalizarse de manera efectiva a situaciones del mundo real debido a las disparidades entre los datos sintéticos y los reales. También podría plantear preocupaciones éticas en algunas de las aplicaciones, como el diagnóstico médico.
¿Cómo ofrece la generación de datos sintéticos ventajas comerciales en términos de costo y escalabilidad?
La recopilación de datos reales es costosa y lenta debido a la asociación entre la implementación de sensores, el etiquetado y la seguridad. Pero los datos sintéticos para el aprendizaje automático en línea se pueden generar fácilmente de forma más económica y rápida. Los datos sintéticos ofrecen fuentes de datos controladas y escalables para un desarrollo sólido de la IA. Por ejemplo, organizaciones como Nvidia y Databricks ofrecen herramientas como Unity Catalog y Omniverse Replicator para automatizar canalizaciones de datos sintéticos. Se estima que entre el 50% y el 60% de los datos utilizados para entrenar plataformas de IA son sintéticos. Su demanda está aumentando a medida que ayuda a las organizaciones a simular nuevos productos, acelerar el desarrollo de modelos de IA y proteger información confidencial.
En octubre de 2025, GenRocket anunció el lanzamiento de su Acelerador de datos no estructurados (UDA), que ha llevado a la organización de generación de datos sintéticos basada en el diseño a expandir su plataforma más allá de los datos estructurados a imágenes, documentos y formatos basados en archivos. Ha ayudado a la organización a generar cualquier tipo de datos de forma segura, precisa y a escala según demanda.
Resumen del informe de mercado de generación de datos sintéticos
Segmentación
Detalles
Por datos
Datos tabulares, datos de texto, datos de imágenes y videos, otros
Por aplicación
Gestión de datos de prueba, formación y desarrollo de IA, intercambio de datos empresariales, análisis y visualización de datos
Por usuario final
Servicios financieros, comercio minorista, atención médica y otros
Por región
América del norte: Estados Unidos, Canadá, México
Europa: Francia, Reino Unido, España, Alemania, Italia, Rusia, Resto de Europa
Asia-Pacífico: China, Japón, India, Australia, ASEAN, Corea del Sur, Resto de Asia-Pacífico
Medio Oriente y África: Turquía, Emiratos Árabes Unidos, Arabia Saudita, Sudáfrica, resto de Medio Oriente y África
Sudamerica: Brasil, Argentina, Resto de Sudamérica
Segmentación del mercado
Por datos (datos tabulares, datos de texto, datos de imágenes y videos, y otros): el segmento de datos tabulares generó 200 millones de dólares en ingresos en 2025, principalmente debido a su creciente adopción en los sectores de comercio electrónico y atención médica. Se utiliza principalmente para entrenar eficazmente algunos modelos de aprendizaje automático.
Por aplicación (gestión de datos de prueba, capacitación y desarrollo de IA, intercambio de datos empresariales y visualización y análisis de datos): el segmento de capacitación y desarrollo de IA está preparado para registrar una asombrosa CAGR del 38,08% durante el período de pronóstico, impulsado por su amplio requisito en la capacitación de modelos de aprendizaje automático. Sirve como una solución potencial para escenarios en los que se necesitan datos, pero hay escasez de datos del mundo real de alta calidad para entrenar modelos de IA.
Por usuario final (servicios financieros, comercio minorista, atención médica y otros): se estima que el segmento de servicios financieros tendrá una participación del 32,13 % para 2032, impulsado por las ventajas de los datos sintéticos, como el intercambio seguro de datos y el desarrollo de modelos para la evaluación de riesgos, la detección de fraude y el análisis sin exponer la información real del cliente. La generación de datos sintéticos puede ser posible para eventos poco comunes, como caídas del mercado o formas de fraude complejas, lo que ayuda a mejorar el rendimiento del modelo y acelerar el desarrollo de la IA.
¿Cuál es el escenario del mercado en América del Norte y la región de Asia Pacífico?
Según la región, el mercado mundial de generación de datos sintéticos se ha clasificado en América del Norte, Europa, Asia Pacífico, Medio Oriente y África y América del Sur.
El mercado de generación de datos sintéticos de América del Norte representó una participación del 38,04% en 2025, valorado en 220 millones de dólares. Este predominio se atribuye a una combinación de infraestructura tecnológica avanzada y una mayor inversión en I+D en la región. En Estados Unidos, en particular, las empresas están adoptando las últimas tecnologías para disminuir los riesgos y la ineficiencia.
Además, los consumidores prefieren apoyar marcas que se centran en innovaciones incrementales. En el comercio minorista, la generación de datos sintéticos ayuda a analizar las preferencias de los clientes, como los hábitos de compra y la demanda estacional, al tiempo que protege la privacidad. La región tiene crecientes obligaciones de privacidad de datos y un sólido ecosistema de IA, lo que está creando un entorno favorable para el crecimiento del mercado.
En junio de 2021, CVEDIA anunció una solución para la brecha de adopción de dominios utilizando el canal de datos sintéticos patentado. Pueden ayudar en el desarrollo de la IA al permitir que los algoritmos entrenados con datos sintéticos funcionen junto con los entrenados con datos reales. CVEDIA afirmó una mejora en la precisión del 170 % y mantuvo una ganancia del 160 % en la recuperación en comparación con los modelos de referencia.
Se espera que el mercado de generación de datos sintéticos de Asia y el Pacífico crezca a una tasa compuesta anual del 38,08% durante el período previsto. Este notable crecimiento está respaldado por el creciente uso de datos sintéticos en varios dominios de la región, como la atención médica, la manufactura, etc.
Por ejemplo, en el sector sanitario, los datos sintéticos se generan para crear registros de pacientes realistas, que ayudan a la investigación y al mismo tiempo ofrecen anonimización y agregación. Ayuda a los investigadores médicos a desarrollar y probar algoritmos para diagnóstico y tratamiento siguiendo las estrictas normas de protección de datos.
En la fabricación, las empresas automovilísticas utilizan datos sintéticos para simular una serie de escenarios de conducción para los coches autónomos. Ayuda a entrenar modelos de aprendizaje automático para reconocer y responder a varias condiciones sin la necesidad de una recopilación extensa de datos del mundo real. Empresas como Waymo y Tesla están revolucionando el uso de datos sintéticos para entrenar sus vehículos autónomos.
Marcos regulatorios
El Reglamento General de Protección de Datos (GDPR) tiene control sobre el procesamiento de datos personales en la UE y define lo que se considera datos anonimizados o sintéticos.
La Ley de Datos (Uso y Acceso) de 2025 en el Reino Unido se ocupa de las disposiciones relacionadas con el procesamiento y el acceso a datos personales y comerciales. Actualiza el marco existente del RGPD y la Ley de Protección de Datos del Reino Unido.
En Estados Unidos (California), la Ley de Privacidad del Consumidor de California (CCPA) y su enmienda, la Ley de Derechos de Privacidad de California (CPRA) rigen la recopilación y el uso de datos personales.
Panorama competitivo
Los actores clave en el mercado de generación de datos sintéticos se están centrando en gran medida en la innovación tecnológica continua. Hay muchos actores pequeños y medianos que se dirigen a tipos y sectores de datos particulares. Los proveedores especializados no tienen una cuota de mercado dominante y operan en segmentos especializados.
Las grandes plataformas de nube e inteligencia artificial, como Microsoft y NVIDIA, entre otras, tienen una parte clave en el mercado, ya que las capacidades de datos sintéticos están presentes dentro de servicios más amplios de inteligencia artificial y aprendizaje automático. La atención también se centra en asociaciones y adquisiciones para obtener ventajas estratégicas.
En marzo de 2025, Nvidia adquirió Gretel, una startup de datos sintéticos, por más de 320 millones de dólares, que está ayudando a su conjunto de servicios de IA generativa para desarrolladores. Gretel mantiene asociaciones con los principales proveedores de la nube, como Google Cloud, Amazon Web Services y Microsoft.
Empresas clave en el mercado de generación de datos sintéticos:
En abril de 2023, MDClone anunció que su plataforma ADAMS está permitiendo un mayor número de asociaciones entre organizaciones de proveedores de atención médica y empresas de ciencias biológicas para acelerar la investigación y el desarrollo terapéutico.
Preguntas frecuentes
¿Cuáles son los impulsores clave del mercado Generación de datos sintéticos?
¿Qué regiones son fundamentales para el crecimiento de la generación de datos sintéticos?
¿Qué desafíos enfrenta hoy la industria de generación de datos sintéticos?
¿Qué tendencias están dando forma al futuro de la generación de datos sintéticos?
¿Quiénes son los principales actores de este sector?
¿Qué oportunidades existen para los inversores?
¿Cómo me ayuda este informe a centrar nuestra estrategia de crecimiento en la región geográfica más prometedora?
¿Cómo me ayuda este informe a comprender qué categoría de DATOS tiene el mayor impacto económico?
Autor
Ashim supervisa los compromisos de inteligencia de mercado personalizados y sindicados desde el diseño hasta la entrega. Se especializa en inteligencia de mercado, modelos de crecimiento, estrategia competitiva y apoyo a las decisiones ejecutivas. Su enfoque de liderazgo enfatiza la claridad de pensamiento y el impacto empresarial mensurable.
Con más de una década de liderazgo en investigación en mercados globales, Ganapathy aporta juicio agudo, claridad estratégica y profunda experiencia en la industria. Conocido por su precisión y compromiso inquebrantable con la calidad, guía a equipos y clientes con insights que impulsan consistentemente resultados empresariales impactantes.