Market Definition
Speech recognition refers to the technological capability to convert spoken language into written text, while voice recognition involves identifying individuals based on distinct vocal characteristics. The market encompasses hardware, software, and services that interpret and process human speech.
Key applications include virtual assistants, automated transcription, in-vehicle voice systems, and biometric authentication. These technologies are utilized across various industries such as healthcare, finance, retail, and enterprise for command execution and secure user verification.
Speech and Voice Recognition Market Overview
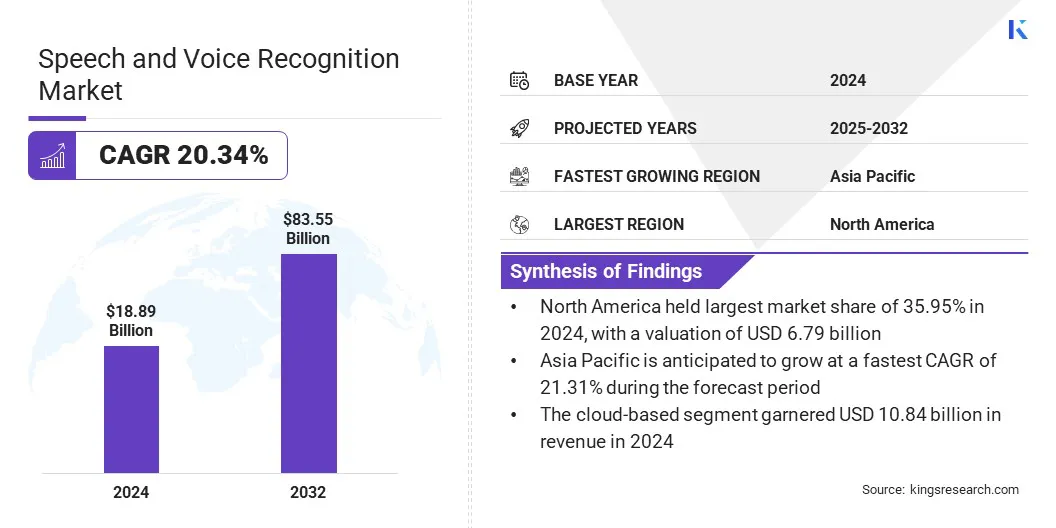
The global speech and voice recognition market size was valued at USD 18.89 billion in 2024 and is projected to grow from USD 22.65 billion in 2025 to USD 83.55 billion by 2032, exhibiting a CAGR of 20.34% during the forecast period.
The market is experiencing significant growth, driven by the rising integration of voice-enabled technologies across consumer electronics, automotive systems, and enterprise applications. Increased adoption of smart assistants, advancements in natural language processing, and the growing demand for contactless interfaces are fueling market expansion.
Key Highlights
- The speech and voice recognition industry size was valued at USD 18.89 billion in 2024.
- The market is projected to grow at a CAGR of 20.34% from 2025 to 2032.
- North America held a share of 35.95% in 2024, valued at USD 6.79 billion.
- The speech recognition segment garnered USD 10.18 billion in revenue in 2024.
- The cloud-based segment is expected to reach USD 46.23 billion by 2032.
- The healthcare segment is projected to generate a revenue of USD 14.11 billion by 2032.
- Asia Pacific is anticipated to grow at a CAGR of 21.31% over the forecast period.
Major companies operating in the speech and voice recognition industry are Apple Inc., Amazon.com, Inc., Alphabet Inc., Microsoft, IBM, Baidu, iFLYTEK Corporation, SAMSUNG, Meta, SoundHound AI Inc., Sensory Inc., Speechmatics, Verint Systems Inc., Cisco Systems, Inc., and OpenAI.
Voice-based solutions enhance user experience, operational efficiency, and data security in the financial sector by enabling natural, hands-free interactions that simplify account access and transactions. They automate routine tasks, reducing reliance on human agents, and lower service costs. Additionally, voice recognition provides biometric authentication, ensuring secure access to sensitive information and reinforcing trust in digital banking.
- For instance, in April 2025, Omniwire, Inc. partnered with NowutalkAI, Inc. to launch the first AI Voice Personal Banker using NowutalkAI’s ‘Voice to Action’ technology. The multilingual, conversational assistant is offered as a white-label solution for banks, fintechs, and credit unions, enabling secure, voice-first banking through Omniwire’s cloud-based Banking-as-a-Service platform.
This development demonstrates the integration of advanced voice technologies into core banking platforms addresses the demand for secure, efficient, and user-friendly financial services, thereby driving the growth of the market.
Market Driver
Rising Adoption of AI-Powered Virtual Assistants
The progress of the global speech and voice recognition market is primarily fueled by the increasing integration of AI-powered virtual assistants in consumer electronics and smart devices.
As businesses and households adopt smart speakers, smartphones, and in-car infotainment systems, the demand for accurate and responsive voice interfaces rises. These AI-enabled systems enhance user experience by enabling hands-free operations, efficient information retrieval, and real-time task execution, fostering convenience and accessibility.
The integration of advanced natural language processing (NLP) and machine learning algorithms allows these systems to understand contextual speech, accents, and user commands with high accuracy. Additionally, companies are focusing on building more personalized and context-aware voice interfaces that align with evolving user expectations. This growing reliance on voice-based technologies significantly contributes to market expansion.
- In February 2025, Amazon launched Alexa+, a generative AI-powered assistant designed for natural, intelligent voice interactions. Integrated with advanced LLMs, Alexa+ enhances task automation, smart home control, and personalized assistance across devices. This upgrade aims to deliver seamless, real-time conversational experiences.
Market Challenge
Accent and Contextual Limitations in Speech Recognition
A major challenge impeding the development of the speech and voice recognition market is the accurate interpretation of diverse accents, dialects, and context-dependent language usage. This often leads to reduced accuracy, particularly in multilingual settings or environments with high ambient noise levels, affecting user experience and system reliability.
To address this challenge, companies are developing advanced natural language processing (NLP) models that incorporate deep learning techniques and are trained on extensive, linguistically diverse datasets. These models are designed to improve the system’s ability to recognize nuanced speech variations and understand user intent more effectively.
Furthermore, improvements in contextual awareness are enabling systems to better interpret conversational cues, supporting wider accessibility and real-world performance.
- In March 2025, OpenAI introduced a new suite of next-generation audio models through its API, featuring state-of-the-art speech-to-text and text-to-speech capabilities. Designed for high accuracy and reliability in challenging acoustic conditions, the release supports the development of customizable and intelligent voice agents across diverse applications.
Market Trend
Integration of Speech Recognition in the Healthcare Industry
The global speech and voice recognition market is influenced by the integration of voice AI technologies within healthcare systems. This trend is boosting the adoption of advanced voice-enabled tools that streamline clinical workflows, reduce administrative burdens, and enhance patient engagement.
Integrating speech recognition capabilities into electronic health record (EHR) platforms and clinical documentation processes improves accuracy, expedites data entry, and boosts clinician productivity.
The ability of these systems to interpret natural language, support multilingual communication, and automate repetitive tasks significantly enhances operational efficiency and care quality. Furthermore, the growing demand for ambient and hands-free solutions in healthcare settings is fostering continued investment in voice-enabled healthcare applications, positioning speech and voice recognition as a critical component in the digital transformation of global health services.
- In March 2025, Microsoft Corp. introduced Dragon Copilot, an AI-powered voice assistant for clinical workflows. The solution integrates Dragon Medical One and DAX Copilot to streamline documentation, automate administrative tasks, and enhance clinician efficiency. Built on Microsoft Cloud for Healthcare, Dragon Copilot combines ambient listening, natural language processing, and generative AI to improve both provider well-being and patient outcomes.
Speech and Voice Recognition Market Report Snapshot
|
Segmentation
|
Details
|
|
By Technology
|
Speech Recognition, Voice Recognition
|
|
By Deployment
|
Cloud-based, On-premises
|
|
By Vertical
|
Healthcare, IT & Telecommunications, Automotive, BFSI, Government & Legal, Education, Retail, Media & Entertainment, Others
|
|
By Region
|
North America: U.S., Canada, Mexico
|
|
Europe: France, UK, Spain, Germany, Italy, Russia, Rest of Europe
|
|
Asia-Pacific: China, Japan, India, Australia, ASEAN, South Korea, Rest of Asia-Pacific
|
|
Middle East & Africa: Turkey, U.A.E., Saudi Arabia, South Africa, Rest of Middle East & Africa
|
|
South America: Brazil, Argentina, Rest of South America
|
Market Segmentation
- By Technology (Speech Recognition and Voice Recognition): The speech recognition segment earned USD 10.18 billion in 2024 due to its widespread adoption in virtual assistants, transcription services, and customer service automation across industries.
- By Deployment (Cloud-based and On-premises): The cloud-based segment held a share of 57.37% in 2024, fueled by its scalability, ease of integration, and lower upfront infrastructure costs.
- By Vertical (Healthcare, IT & Telecommunications, Automotive, BFSI, Government & Legal, Education, Retail, Media & Entertainment, and Others): The healthcare segment is projected to reach USD 14.11 billion by 2032, owing to the increasing use of speech-enabled clinical documentation and voice-driven patient engagement tools.
Speech and Voice Recognition Market Regional Analysis
Based on region, the market has been classified into North America, Europe, Asia Pacific, Middle East & Africa, and South America.
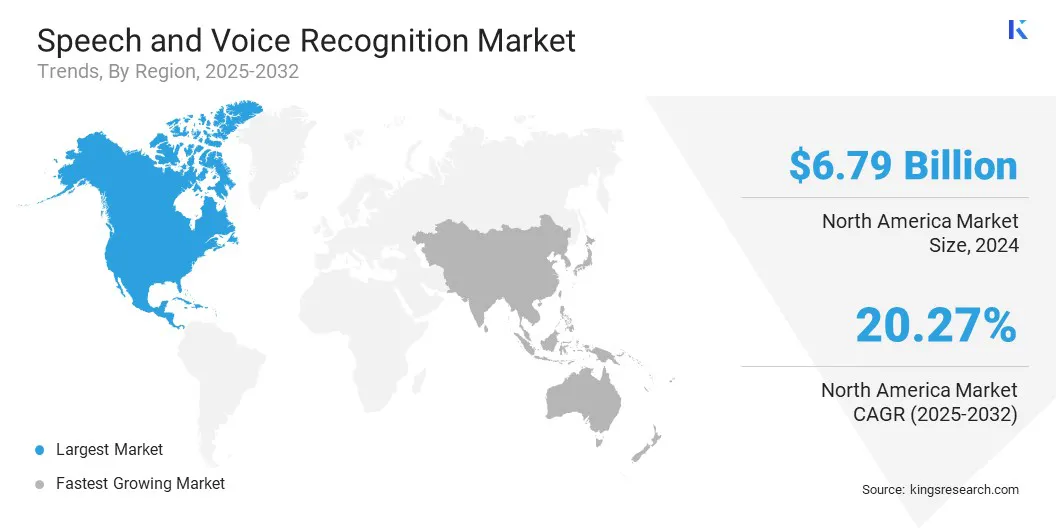
The North America speech and voice recognition market accounted for a substantial share of 35.95% in 2024, valued at USD 6.79 billion. This dominance is reinforced by strong investment in artificial intelligence and natural language processing technologies, which have significantly advanced the capabilities of voice-enabled systems.
These innovations are increasingly being integrated into consumer electronics, enterprise software, and digital services, promoting seamless, hands-free user experiences. The availability of high digital infrastructure, skilled talent, and early technology adoption further accelerates this trend.
With voice emerging as a primary interface for device and application interaction, North American businesses and consumers are adopting speech and voice recognition tools, solidifying the region's leading position.
- In January 2025, ElevenLabs raised USD 180 million in Series C funding to advance its AI audio technology, expand its research, and develop new products that make voice and sound central to digital interactions.
The Asia-Pacific speech and voice recognition industry is expected to register the fastest CAGR of 21.31% over the forecast period. This growth is primarily fostered by the expanding smartphone penetration and the integration of voice assistants in mobile devices.
With a large and growing population of mobile-first users, especially in countries such as China, India, and Southeast Asian nations, there is a strong demand for intuitive and localized voice interaction. Manufacturers and service providers are integrating voice recognition features to enhance accessibility, user convenience, and personalization in native languages and dialects.
This mobile-centric voice interface trend is transforming digital engagement across sectors such as e-commerce, banking, healthcare, and education. The rise of affordable smartphones with embedded AI capabilities further fuels this growth.
- In December 2023, A*STAR’s Institute for Infocomm Research, IMDA, and AI Singapore partnered to launch Southeast Asia’s first regional large language model under Singapore’s National Multimodal LLM Programme. The initiative aims to develop culturally contextual speech–text models tailored to Southeast Asian languages, enhancing local voice interaction capabilities.
Regulatory Frameworks
- In the U.S., the Federal Trade Commission (FTC) and Federal Communications Commission (FCC) regulate voice technologies under consumer protection and communications laws, focusing on privacy, surveillance, and fair business practices.
- In Europe, the General Data Protection Regulation (GDPR) governs the collection, processing, and storage of voice data, requiring companies to ensure transparency, user consent, and data minimization when deploying voice recognition technologies.
- In China, the Cyberspace Administration of China (CAC) enforces the Personal Information Protection Law (PIPL), which includes strict requirements for biometric data such as voice, ensuring local data storage and user consent.
- In Japan, the Personal Information Protection Commission (PPC) oversees the Act on the Protection of Personal Information (APPI), which regulates voice data use, particularly in applications involving biometric authentication or voice profiling.
Competitive Landscape
The global speech and voice recognition industry is characterized by rapid technological innovation, supported by the increasing integration of voice interfaces into everyday devices and enterprise solutions.
Companies are actively collaborating with AI research institutions and cloud service providers to co-develop advanced voice-enabled applications, aiming to deliver faster, more accurate, and context-aware speech processing. These collaborations are enabling firms to enhance voice analytics capabilities and improve system responsiveness across diverse environments such as call centers, automobiles, and smart devices.
Companies are further launching purpose-built voice recognition platforms that can be easily embedded into enterprise workflows, offering scalability and multilingual adaptability. This ongoing shift toward integration, customizability, and performance optimization is intensifying competition, with players striving to differentiate themselves through proprietary models and region-specific voice solutions tailored to user needs.
- In March 2025, Kyndryl collaborated with Microsoft to launch Dragon Copilot, an AI-powered healthcare assistant leveraging generative AI for ambient listening and voice recognition. The partnership aims to automate clinical documentation, enhance clinician efficiency, and improve patient care by integrating voice dictation and natural language capabilities into healthcare workflows.
- In September 2024, Deepgram launched its Voice Agent API, a unified voice-to-voice solution enabling real-time, natural-sounding conversations between humans and machines. The API integrates advanced speech recognition and voice synthesis to help enterprises and developers build intelligent voicebots and AI agents for applications such as customer support and order processing.
Key Companies in Speech and Voice Recognition Market:
- Apple Inc.
- Amazon.com, Inc.
- Alphabet Inc.
- Microsoft
- IBM
- Baidu
- iFLYTEK Corporation
- SAMSUNG
- Meta
- SoundHound AI Inc.
- Sensory Inc.
- Speechmatics
- Verint Systems Inc.
- Cisco Systems, Inc.
- OpenAI
Recent Developments (Product Launches/Collaborations)
- In April 2025, aiOla introduced Jargonic, a foundation ASR model designed for real-time, domain-specific transcription using keyword spotting and zero-shot learning. Jargonic offers superior performance in noisy industrial settings, handles multilingual speech recognition, and outperforms competitors in word error rate and jargon term recall without requiring retraining for new industry vocabularies.
- In April 2025, Kia expanded its generative AI-powered voice recognition system, AI Assistant, to the European market via Over-the-Air updates. Initially introduced in Korea and the United States, the system enables natural interaction and enhanced vehicle control, and will be available on EV3 models and other ccNC-equipped models.
- In April 2025, IntelePeer launched advanced voice AI capabilities featuring automatic speech recognition (ASR) and text-to-speech (TTS) streaming. Developed in-house, the technology enables real-time conversations, enhances customer experience through natural interactions and low latency, and strengthens the company’s end-to-end conversational AI platform with improved analytics, language detection, and customizable automation settings.
- In June 2024, Philips Speech by Speech Processing Solutions collaborated with Sembly AI to launch three new audio recorders integrated with AI technology. The devices offer automatic transcriptions, summaries, action lists, and insights, while Sembly AI adds speaker separation, meeting notes, and productivity-enhancing features.


