Размер рынка генерации синтетических данных, доля, рост и отраслевой анализ, по данным (табличные данные, текстовые данные, изображения и видеоданные, другие), по приложениям (управление тестовыми данными, обучение и разработка искусственного интеллекта, обмен корпоративными данными, аналитика и визуализация данных), по конечным пользователям (финансовые услуги, розничная торговля, здравоохранение и другие) и региональный анализ, 2026-2033
Страницы: 180 | Базовый год: 2025 | Релиз: февраль 2026 г. | Автор: Ashim L. | Последнее обновление: март 2026 г.
Синтетические данные — это искусственные данные, предназначенные для имитации реальных данных. Он создается искусственно, но сохраняет статистические свойства исходных данных, на основе которых он был создан. Генерация синтетических данных может происходить в табличной, мультимедийной или текстовой форме. Синтетические текстовые данные могут быть полезны для обработки естественного языка (NLP). Аналогичным образом, табличные данные применяются при создании таблиц реляционной базы данных.
Синтетические мультимедиа включают изображения, видео и другие неструктурированные данные, которые могут иметь решающее значение для задач компьютерного зрения, таких как распознавание изображений и классификация изображений, среди прочего. В таких секторах, как финансы, здравоохранение и розничная торговля, растут требования к данным. Синтетические данные помогают таким организациям, ускоряя инновации в области искусственного интеллекта и позволяя принимать более взвешенные решения.
Рынок генерации синтетических данныхОбзор
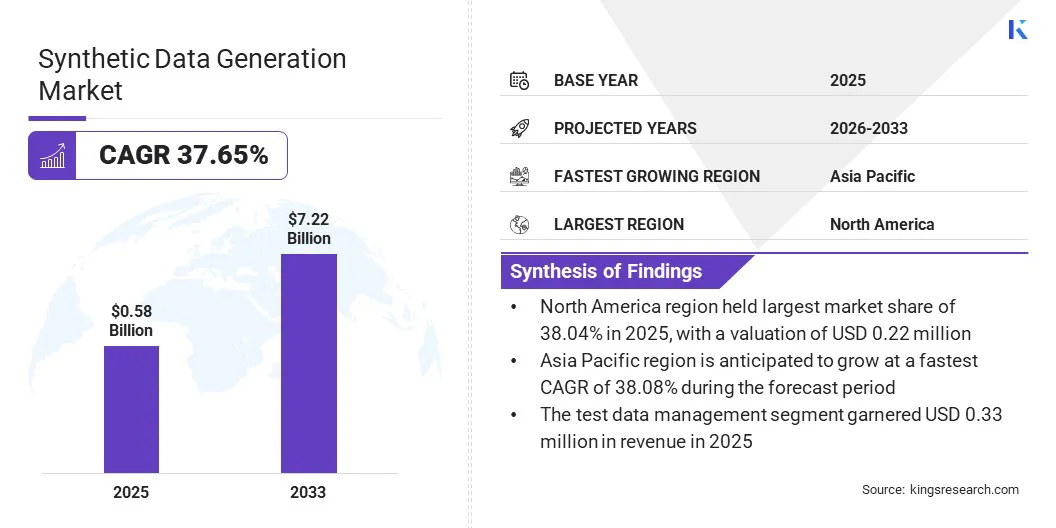
Объем мирового рынка генерации синтетических данных оценивался в 0,58 млрд долларов США в 2025 году и, по прогнозам, вырастет с 0,77 млрд долларов США в 2026 году до 7,22 млрд долларов США к 2033 году, демонстрируя среднегодовой темп роста 37,65% в течение прогнозируемого периода. Этот рост объясняется его применением для тестовых систем, обучения моделей ИИ и моделирования сценариев, которые, как правило, трудно отразить в реальных данных.
Например, в секторе здравоохранения синтетические медицинские записи могут обозначать такие состояния, как диабет, болезни или рак, что может помочь в разработке и тестировании диагностических инструментов наряду с моделями прогнозирования здоровья.
Основными компаниями, работающими на мировом рынке генерации синтетических данных, являются MOSTLY AI, Datagen, TonicAI, Inc., GenRocket, Inc, NVIDIA (Gretel Labs), K2view Ltd, CapGemini (Sogeti), CVEDIA Inc, Microsoft Corporation и MDClone и другие.
Ожидается, что спрос на синтетические данные будет расти по мере их растущего использования в нескольких секторах, включая автомобильный сектор для тестированияавтономные транспортные средства, здравоохранение для анализа медицинских изображений и диагностики пациентов. В секторе розничной торговли он в основном используется для управления инвестициями и анализа поведения клиентов.
Это может быть полезно в сфере финансов для обнаружения мошенничества и оценки рисков. Ключевое преимущество синтетических данных — экономическая эффективность, масштабируемость и разнообразие. Они в основном используются при обучении моделей машинного обучения. Он обеспечивает больший контроль над качеством данных, а также сохраняет конфиденциальность, исключая использование реальных конфиденциальных данных.
Последняя тенденция указывает на интеграцию федеративного обучения и дифференцированной конфиденциальности для улучшения машинного обучения, сохраняющего конфиденциальность. Кроме того, спрос на разнообразные и высококачественные наборы обучающих данных будет расти по мере распространения ИИ в новых областях, что делает синтетические данные очень важными.
Ключевые моменты:
В 2025 году объем мирового рынка генерации синтетических данных составил 0,58 миллиарда долларов США.
Прогнозируется, что в период с 2026 по 2033 год рынок будет расти в среднем на 37,65%.
В 2025 году доля Северной Америки составила 38,04% на сумму 0,22 миллиарда долларов США.
Сегмент табличных данных в 2025 году принес доход в размере 0,20 млрд долларов США.
Ожидается, что к 2033 году сегмент управления тестовыми данными достигнет 4,05 миллиарда долларов США.
Ожидается, что в сегменте здравоохранения будет наблюдаться самый быстрый среднегодовой темп роста (38,28%) за прогнозируемый период.
Ожидается, что в течение прогнозируемого периода среднегодовой темп роста в Азиатско-Тихоокеанском регионе составит 38,08%.
Насколько надежны синтетические данные для обучения ИИ?
Синтетические данные, созданные с использованием надежных методов, могут соответствовать реальным данным или, в некоторых случаях, превосходить их по производительности модели, особенно в сценариях с редкими событиями.
Хотя он не может заменить реальные данные, он очень эффективен при поддержке реальных данных, особенно когда команда имеет дело с ограниченными данными, несбалансированными наборами данных или ограничениями конфиденциальности. В результате он может работать как мощное дополнение к реальным данным, а не как их полная замена.
В октябре 2024 года MOSTLY AI представила новую функцию синтетического текста для обучения моделей ИИ, а также заботится о конфиденциальности собственных данных. Это помогает организации использовать широкий спектр текстовых данных, таких как электронные письма, разговоры в чат-ботах, стенограммы поддержки клиентов и т. д., для обучения и точной настройкибольшие языковые модели (LLM), и нет риска нарушения конфиденциальности.
Почему обучение систем искусственного интеллекта требует осознания того, что синтетические данные могут давать ложные результаты?
Синтетическим данным может не хватать сложности и нюансов реальных данных, что может привести к плохой работе моделей ИИ в реальных сценариях. Более того, существует вероятность того, что модели ИИ, полностью обученные на синтетических данных, не смогут эффективно обобщаться на реальные ситуации из-за несоответствия между синтетическими и фактическими данными. Это также может вызвать этические проблемы в некоторых приложениях, таких как медицинская диагностика.
Каким образом генерация синтетических данных дает бизнес-преимущества с точки зрения стоимости и масштабируемости?
Реальный сбор данных является дорогостоящим и медленным, поскольку он связан с развертыванием датчиков, маркировкой и безопасностью. Но синтетические данные для онлайн-машинного обучения можно легко генерировать дешевле и быстрее. Синтетические данные предлагают контролируемые и масштабируемые источники данных для надежной разработки ИИ. Например, такие организации, как Nvidia и Databricks, предлагают такие инструменты, как Unity Catalog и Omniverse Replicator, для автоматизации конвейеров синтетических данных. По оценкам, от 50% до 60% данных, используемых для обучения платформ ИИ, являются синтетическими. Спрос на него растет, поскольку он помогает организациям моделировать новые продукты, ускорять разработку моделей искусственного интеллекта и защищать конфиденциальную информацию.
В октябре 2025 года GenRocket объявила о запуске своего ускорителя неструктурированных данных (UDA), который позволил организации по созданию синтетических данных, ориентированной на дизайн, расширить свою платформу за пределы структурированных данных до изображений, документов и файловых форматов. Это помогло организации безопасно, точно и в нужном масштабе генерировать любые данные.
Снимок отчета о рынке генерации синтетических данных
Сегментация
Подробности
По данным
Табличные данные, текстовые данные, данные изображений и видео, другие
По применению
Управление тестовыми данными, обучение и разработка искусственного интеллекта, обмен корпоративными данными, анализ и визуализация данных
По конечному пользователю
Финансовые услуги, розничная торговля, здравоохранение и другие
По регионам
Северная Америка: США, Канада, Мексика
Европа: Франция, Великобритания, Испания, Германия, Италия, Россия, Остальная Европа.
Азиатско-Тихоокеанский регион: Китай, Япония, Индия, Австралия, АСЕАН, Южная Корея, остальные страны Азиатско-Тихоокеанского региона.
Ближний Восток и Африка: Турция, ОАЭ, Саудовская Аравия, Южная Африка, остальной Ближний Восток и Африка.
Южная Америка: Бразилия, Аргентина, остальная часть Южной Америки.
Сегментация рынка
По данным (табличные данные, текстовые данные, изображения и видеоданные и другие). Сегмент табличных данных принес в 2025 году доход в размере 0,20 млрд долларов США, главным образом благодаря его растущему распространению в секторах электронной коммерции и здравоохранения. Он в основном используется для эффективного обучения некоторых моделей машинного обучения.
По приложениям (управление тестовыми данными, обучение и разработка ИИ, совместное использование корпоративных данных, а также аналитика и визуализация данных): сегмент обучения и разработки ИИ готов зафиксировать ошеломляющий среднегодовой темп роста в 38,08% в течение прогнозируемого периода, что обусловлено его широкими потребностями в обучении моделей машинного обучения. Он служит потенциальным решением для сценариев, в которых требуются данные, но не хватает высококачественных реальных данных для обучения моделей ИИ.
По конечным пользователям (финансовые услуги, розничная торговля, здравоохранение и другие): по оценкам, к 2032 году доля сегмента финансовых услуг составит 32,13%, чему способствуют такие преимущества синтетических данных, как безопасный обмен данными и разработка моделей для оценки рисков, обнаружения мошенничества и анализа без раскрытия реальной информации о клиентах. Генерация синтетических данных может быть возможна для редких событий, таких как обвалы рынка или сложные формы мошенничества, что помогает улучшить производительность модели и ускорить разработку ИИ.
Каков сценарий развития рынка в Северной Америке и Азиатско-Тихоокеанском регионе?
В зависимости от региона мировой рынок генерации синтетических данных подразделяется на Северную Америку, Европу, Азиатско-Тихоокеанский регион, Ближний Восток и Африку и Южную Америку.
Доля рынка генерации синтетических данных Северной Америки в 2025 году составила 38,04% и оценивалась в 0,22 миллиарда долларов США. Такое доминирование объясняется сочетанием передовой технологической инфраструктуры и увеличением инвестиций в НИОКР в регионе. В частности, в США предприятия внедряют новейшие технологии для снижения рисков и неэффективности.
Более того, потребители предпочитают поддерживать бренды, которые ориентированы на постепенные инновации. В розничной торговле генерация синтетических данных помогает анализировать предпочтения клиентов, такие как покупательские привычки и сезонный спрос, одновременно защищая конфиденциальность. В регионе растут обязательства по конфиденциальности данных и сильная экосистема искусственного интеллекта, которая создает благоприятную среду для роста рынка.
В июне 2021 года CVEDIA объявила о решении проблемы внедрения доменов с использованием собственного конвейера синтетических данных. Они могут помочь в развитии ИИ, позволяя алгоритмам, обученным на синтетических данных, работать так же, как и алгоритмам, обученным на реальных данных. CVEDIA заявила об улучшении точности на 170 % и сохранении прироста отзыва на 160 % по сравнению с эталонными моделями.
В течение прогнозируемого периода среднегодовой темп роста рынка генерации синтетических данных в Азиатско-Тихоокеанском регионе составит 38,08%. Этот заметный рост поддерживается растущим использованием синтетических данных в нескольких областях региона, таких как здравоохранение, производство и т. д.
Например, в здравоохранении синтетические данные генерируются для создания реалистичных записей пациентов, которые помогают проводить исследования, обеспечивая при этом анонимность и агрегирование. Он помогает исследователям-медикам разрабатывать и тестировать алгоритмы диагностики и лечения, соблюдая при этом строгие правила защиты данных.
В производстве автомобильные компании используют синтетические данные для моделирования ряда сценариев вождения беспилотных автомобилей. Это помогает обучать модели машинного обучения распознаванию и реагированию на несколько условий без необходимости обширного сбора реальных данных. Такие компании, как Waymo и Tesla, совершают революцию в использовании синтетических данных для обучения своих беспилотных автомобилей.
Нормативно-правовая база
Общий регламент по защите данных (GDPR) контролирует обработку персональных данных в ЕС и определяет, что квалифицируется как анонимные или синтетические данные.
Закон о данных (использовании и доступе) 2025 года в Великобритании регулирует положения, касающиеся обработки и доступа к личным и деловым данным. Он обновляет существующую структуру GDPR и Закона о защите данных Великобритании.
В США (Калифорния) сбор и использование персональных данных регулируется Законом Калифорнии о конфиденциальности потребителей (CCPA) и поправкой к нему, Законом Калифорнии о правах на конфиденциальность (CPRA).
Конкурентная среда
Ключевые игроки на рынке генерации синтетических данных в основном сосредоточены на постоянных технологических инновациях. Есть много мелких и средних игроков, которые ориентируются на определенные типы данных и сектора. Специализированные поставщики не занимают доминирующую долю рынка и работают в нишевых сегментах.
Крупные облачные платформы и платформы искусственного интеллекта, такие как Microsoft и NVIDIA, среди прочих, занимают ключевую долю на рынке, поскольку возможности синтетических данных присутствуют в более широких сервисах искусственного интеллекта и машинного обучения. Основное внимание также уделяется партнерству и приобретениям для получения стратегических преимуществ.
В марте 2025 года Nvidia приобрела Gretel, стартап по производству синтетических данных, за более чем 320 миллионов долларов США, что помогает ее набору генеративных услуг искусственного интеллекта для разработчиков. Gretel поддерживает партнерские отношения с крупными поставщиками облачных услуг, такими как Google Cloud, Amazon Web Services и Microsoft.
Ключевые компании на рынке генерации синтетических данных:
В апреле 2023 года MDClone объявила, что ее платформа ADAMS обеспечивает большее количество партнерских отношений между организациями, предоставляющими медицинские услуги, и компаниями, работающими в области медико-биологических наук, для ускорения терапевтических исследований и разработок.
Часто задаваемые вопросы
Каковы ключевые факторы на рынке Генерация синтетических данных?
Какие регионы имеют решающее значение для роста производства синтетических данных?
С какими проблемами сегодня сталкивается индустрия генерации синтетических данных?
Как этот отчет поможет мне сосредоточить нашу стратегию роста на наиболее перспективном географическом регионе?
Как этот отчет поможет мне понять, какая категория ДАННЫХ оказывает наибольшее экономическое влияние?
Автор
Ашим курирует синдицированные и индивидуальные исследования рынка, от проектирования до доставки. Он специализируется на анализе рынка, моделировании роста, конкурентной стратегии и поддержке принятия решений руководителями. Его подход к лидерству подчеркивает ясность мышления и измеримое влияние на бизнес.
Имея более десяти лет опыта руководства исследованиями на глобальных рынках, Ганапати обладает острым суждением, стратегической ясностью и глубокой отраслевой экспертизой. Известный своей точностью и непоколебимой приверженностью качеству, он направляет команды и клиентов с инсайтами, которые постоянно обеспечивают значимые бизнес-результаты.