Размер рынка моделей крупных языков, доля, анализ роста и отрасли, по типу (специфичный для домена, общее назначение, многоязычное), по методам (текст, изображения, аудио), по архитектуре (авторегрессив, автоэкодирование), по применению, по вертикальным и региональным анализу отрасли, в отрасли, вертикальный и региональный анализ, 2024-2031
Страницы: 230 | Базовый год: 2023 | Релиз: апрель 2025 г. | Автор: Versha V. | Последнее обновление: февраль 2026 г.
Рынок охватывает разработку, развертывание и коммерциализацию современных моделей искусственного интеллекта для обработки естественного языка (NLP).
Он включает в себя компании, занимающиеся исследованиями, обучением и оптимизацией LLM, а также поставщики облачных услуг, предлагающих решения на основе LLM через API и корпоративные платформы. Кроме того, рынок охватывает отрасли, внедряющие LLM для таких приложений, как чат -боты, генерация контента и разработка кода.
Рынок моделей крупных языковОбзор
Глобальный размер рынка крупных языковых моделей оценивался в 5,94 млрд долларов США в 2023 году и, по прогнозам, будет расти с 7,73 млрд долларов США в 2024 году до 60,07 млрд долларов к 2031 году, демонстрируя CAGR 34,03% в течение прогнозируемого периода.
Рост рынка обусловлен увеличением внедрения в различных отраслях, таких как технологии, здравоохранение, финансы, розничная торговля и обслуживание клиентов. Растущий спрос на автоматизацию, управляемую AI, улучшенразговорной ИИи расширенные возможности анализа данных - это подпитывание инвестиций в исследования и разработки LLM.
Основными компаниями, работающими в индустрии крупных языковых моделей, являются Microsoft, Mistral AI, Stability Ai Ltd, IBM, AI21 Labs, Anpropic, Google, Eleutherai, G42, Alibaba, Amazon.com, Inc., Deepseek, Meta, Cohere и Lighton.
Интеграция LLMS в бизнес -процессы, создание контента и разработка программного обеспечения расширяет свой коммерческий потенциал. Стратегические партнерские отношения, слияния и государственные инициативы, поддерживающие инновации искусственного интеллекта, еще больше повышают рост рынка, позиционируя LLM в качестве критического компонента в глобальном ландшафте ИИ.
В июне 2024 года Cognizant запустила свои первые решения для больших языковых моделей здравоохранения (LLM) в рамках своего генеративного партнерства с искусственным интеллектом с Google Cloud. Эти решения, основанные на моделях Gemini Google Cloud и платформе AI Vertex, оптимизируют административные процессы здравоохранения и улучшают результаты бизнеса.
Ключевые основные моменты:
Размер индустрии крупных языковых моделей был записан в 5,94 млрд долларов США в 2023 году.
Предполагается, что рынок будет расти на 34,03% с 2024 по 2031 год.
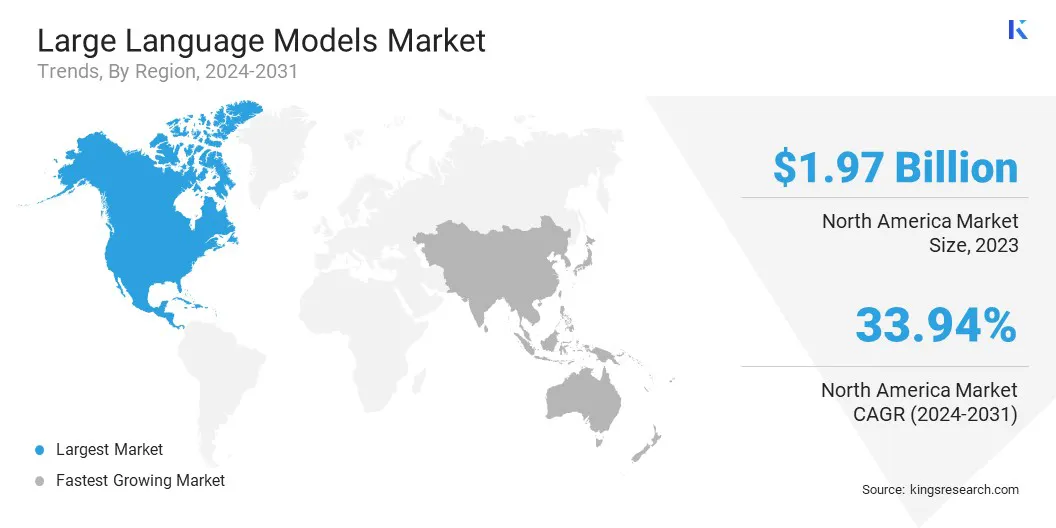
В 2023 году Северная Америка в размере 33,24% стоила 1,97 миллиарда долларов США.
Сегмент общего назначения получил 2,48 миллиарда долларов США в 2023 году.
Ожидается, что текстовый сегмент достигнет 21,27 млрд долларов к 2031 году.
Ауторегрессивный сегмент, по прогнозам, к 2031 году принесет доход в размере 23,13 млрд долларов.
Чат -боты и виртуальный ассистент, вероятно, достигнут 17,47 млрд долларов к 2031 году.
Сегмент здравоохранения получил доход в 1,69 млрд долларов США в 2023 году.
Ожидается, что в Азиатско -Тихоокеанском регионе вырастет на 35,10% в течение прогнозируемого периода.
Рыночный драйвер
«Растущее принятие предприятий и достижения искусственного интеллекта»
Рынок крупных языковых моделей (LLMS) переживает быстрый рост, обусловленное увеличением принятия предприятий и достижений в инфраструктуре искусственного интеллекта. Предприятия в различных отраслях, включая финансы, здравоохранение, электронную коммерцию и обслуживание клиентов, используют LLMS для улучшения автоматизации, улучшения вовлечения клиентов и оптимизации данных.
Способность LLMS генерировать человеческий текст, помощь в принятии решений и персонализировать пользовательский опыт сделала их ценным инструментом для цифрового преобразования.
Кроме того, достижения в области ИИ инфраструктуры и вычислительной мощности поддерживают расширение рынка. Достижения в области высокопроизводительных вычислений (HPC) ресурсов, облачных платформ ИИ и специализированных чипов ИИ (такие как графические процессоры и ТПУ) улучшили эффективность обучения и развертывания LLMS. Эти инновации позволяют разработать более мощные, масштабируемые модели, подпитывая их внедрение и коммерческую жизнеспособность.
Рыночный вызов
«Высокие вычислительные затраты и потребление энергии»
Основной проблемой, препятствующей расширению рынка крупных языковых моделей (LLMS), является высокая вычислительная стоимость и потребление энергии, необходимые для обучения и развертывания. LLM основаны на обширных наборах данных и высокопроизводительных вычислительных ресурсах, что приводит к существенным затратам на инфраструктуру и увеличению углеродных следов.
Опора на специализированное оборудование, такое как графические процессоры и TPU, еще больше повышает затраты, ограничивая доступность для небольших предприятий. Эта задача может быть решена посредством разработки более эффективных модельных архитектур, таких как модели смеси экспертов (MOE), которые активируют лишь часть параметров модели на запрос, снижая вычислительные требования.
Тенденция рынка
«Мультимодальные возможности и инновации с открытым исходным кодом»
Рынок крупных языковых моделей (LLMS) является свидетелем значительного расширения, вызванного ростом мультимодальной LLM и расширения с открытым исходным кодом. Мультимодальные LLM, способные обрабатывать текст, изображения, аудио и видео, получают тягу в создании контента, диагностике здравоохранения и интерактивном ИИ. Эти модели улучшают вовлечение пользователей, предоставляя более богатые, более контекстуальные ответы, увеличивая их коммерческую ценность.
Кроме того, расширение LLMS с открытым исходным кодом способствует инновациям и доступности. Компании и исследовательские институты все чаще выпускают модели с открытым исходным кодом, позволяя разработчикам настраивать и оптимизировать их для конкретных приложений.
Эта тенденция демократизирует ИИ, позволяющая предприятиям, стартапам и исследователям использовать Advanced LLM, не полагаясь исключительно на проприетарные решения, ускоряя глобальные достижения в области ИИ.
В марте 2024 года DataBricks запустила DBRX, общего назначения с открытым исходным кодом (LLM), разработанной ее исследовательской группой Mosaic. DBRX превосходит ведущие LLM с открытым исходным кодом, включая Llama2-70B, GROK-1 и миктрал, в понимании языка, программировании, математике и логике.
Снимок отчета о рынке на крупных языковых моделях
Сегментация
Подробности
По типу
Специфичный домен, общее назначение, многоязычное
По модальности
Текст, изображения, аудио, видео
По архитектуре
Авторегрессивный, автоэкодирующий, гибридный
По приложению
Чат -боты и виртуальный помощник, генерация кода, генерация контента, обслуживание клиентов, языковой перевод, анализ настроений
По отрасли вертикально
Здравоохранение, BFSI, образование, медиа и развлечения, другие
По региону
Северная Америка: США, Канада, Мексика
Европа: Франция, Великобритания, Испания, Германия, Италия, Россия, остальная часть Европы
Азиатско-Тихоокеанский регион: Китай, Япония, Индия, Австралия, АСЕАН, Южная Корея, остальная часть Азиатско-Тихоокеанского региона
Ближний Восток и Африка: Турция, ОАЭ, Саудовская Аравия, Южная Африка, остальная часть Ближнего Востока и Африки
Южная Америка: Бразилия, Аргентина, остальная часть Южной Америки
Сегментация рынка
По типу (специфическая для домена, общее назначение и многоязычное): сегмент общего назначения заработал 2,48 миллиарда долларов США в 2023 году из -за его широкого распространения в нескольких отраслях.
По модальности (текст, изображения, аудио, видео): текстовый сегмент владел 35,56%в 2023 году, что связано с широким использованием LLMS в обработке документов, чат -ботов и генерации контента.
По архитектуре (Autoregressive, AutoEncoding и Hybrid): авторегрессивный сегмент, по прогнозам, к 2031 году достигнет 23,13 млрд. Долл. США из -за его эффективности в создании когерентного и контекстуального точного текста.
По приложению (чат -боты и виртуальный помощник, генерация кода, генерация контента и обслуживание клиентов): чат -боты и сегмент виртуального помощника, по оценкам, к 2031 году принесут доход в размере 17,47 млрд долларов США из -за увеличения внедрения предприятий для привлечения клиентов и автоматизации.
По вертикали промышленности (здравоохранение, BFSI, образование, СМИ и развлечения и другие): сегмент здравоохранения заработал 17,18 млрд долларов США в 2023 году, в основном за счет растущего использования LLMS в медицинских исследованиях, диагностике, клинической документации и взаимодействии с пациентами.
Рынок моделей крупных языковРегиональный анализ
Основываясь на регионе, рынок был классифицирован в Северной Америке, Европе, Азиатско -Тихоокеанском регионе, Ближнем Востоке и Африке и Латинской Америке.
В 2023 году доля рынка крупных языковых моделей в Северной Америке составляла около 33,24%, стоимостью 1,97 миллиарда долларов США. Это доминирование подкрепляется ведущими исследовательскими фирмами ИИ, такими технологическими гигантами, как Google, Microsoft и Meta, и значительные инвестиции в инфраструктуру ИИ иоблачные вычисленияПолем
Региональный рынок далее выгодно от сильного финансирования государственного и частного сектора для достижений искусственного интеллекта, надежной экосистемы стартапов и широко распространенного внедрения LLMS по финансам, здравоохранению и обслуживанию клиентов.
Кроме того, передовая индустрия полупроводниковых и вычислительных аппаратных средств Северной Америки, особенно в США, Accelerate LLM разработка и развертывание, помогая расширению регионального рынка.
Азиатско -тихоокеанская индустрия моделей на крупных языках готова расти с значительным среднем в 35,10% в течение прогнозируемого периода. Этот рост способствует увеличению инвестиций в исследования искусственного интеллекта, государственные инициативы, способствующие цифровым преобразованию, и растущий спрос на автоматизацию, управляемую ИИ, в таких отраслях, как образование, электронная коммерция и телекоммуникации.
Несколько правительств в регионе активно поддерживают развитие ИИ посредством программ финансирования, национальных стратегий ИИ и улучшения инфраструктуры. Страны создают исследовательские центры искусственного интеллекта, продвигают академическую сотрудничество и реализацию политики для продвижения внедрения ИИ в государственных услугах и предприятиях.
Кроме того, крупная база пользователей Интернета, многоязычное разнообразие и растущий спрос на экосистему данных повышает LLMS, адаптированные к местным языкам и приложениям. Улучшенная инфраструктура искусственного интеллекта, в том числе высокоэффективная расширение вычислений, еще больше ускоряет принятие как в предприятиях, так и в потребительских секторах.
В сентябре 2024 года правительство Индии запустило Bharatgen, финансируемую правительством генеративную ИИ инициативу, направленную на улучшение предоставления государственной службы и участия граждан. Как первый индийский финансируемый правительством мультимодальный проект крупной языковой модели, он фокусируется на продвижении ИИ на индийских языках и укреплении позиции страны в генеративном ИИ.
Нормативные рамки
В СШАНациональный институт стандартов и технологий (NIST) регулирует системы искусственного интеллекта, в том числе модели крупных языков (LLMS), посредством структуры управления рисками ИИ (AI RMF), которая подчеркивает надежность, справедливость и прозрачность. Кроме того, Билль о правах ИИ описывает не связывающие принципы для защиты отдельных лиц от вреда от ИИ, сосредоточенного на конфиденциальности данных, алгоритмической предотвращении дискриминации и объяснимость решения.
В ЕвропеАкт ЕС АИТ регулирует крупные языковые модели (LLMS) на основе уровней риска, классифицируя модели фундамента как AI высокого риска или общего назначения. Закон обязывает прозрачность, подотчетность и смягчение смещения для обеспечения этического развертывания ИИ.
Конкурентная ландшафт
Ключевые игроки в индустрии крупных языковых моделей сосредоточены на технологических достижениях, стратегическом партнерстве и крупномасштабных инвестициях в инфраструктуру, чтобы укрепить свою позицию на рынке.
Они в значительной степени инвестируют в обучение и тонкую настройку частных LLM, используя обширные наборы данных для повышения точности модели, эффективности и контекстного понимания.
Основная конкурентная стратегия включает в себя облачные услуги искусственного интеллекта, интеграцию LLM в корпоративные приложения и предложение API и индивидуальные решения для искусственных интеллекта в разных отраслях, таких как здравоохранение, финансы и обслуживание клиентов.
Кроме того, компании расширяют мультимодальные возможности, расширяя LLMS за пределы текста, чтобы включить изображения, аудио и обработку видео для улучшения взаимодействия с пользователями и расширения объема приложений.
Стратегическое сотрудничество с академическими учреждениями, исследовательскими лабораториями ИИ и облачными поставщиками ускоряет инновации. Компании используют рамки с открытым исходным кодом для содействия вовлечению разработчиков, сохраняя при этом запатентованные модели для коммерциализации.
Поскольку конкуренция усиливается, рынок свидетельствует о сдвиге в направлении LLM, специфичных для региона, для поддержки местных языков и культурных контекстов. Кроме того, достижения в области ИИ и обработки на краю и обработки на грани расширяют возможности LLM с более низкой задержкой и повышенной конфиденциальностью.
В августе 2023 года G42 выпустил Jais, самую высокую в мире арабскую большую языковую модель, в качестве проекта с открытым исходным кодом. Разработанный в сотрудничестве с Университетом искусственного интеллекта Мохамеда Бин Зайед (MBZUAI) и системами головного мозга, JAIS имеет 13 миллиардов параметров и обучается на наборе арабского и английского языка на 395 миллиардов.
Список ключевых компаний на рынке крупных языковых моделей:
Последние разработки (партнерские отношения/запуск нового продукта)
В сентябре 2024 года, Fujitsu, в партнерстве с Cohere Inc., представила Takane, передовую модель большой языка (LLM), оптимизированная для предприятий в области безопасных частных сред. Созданный расширенными возможностями японского языка, Takane Top Lop Rankings of японского общего языка понимания оценки оценки (JGLUE).
В июле 2024 года, Международное общество автоматизации запустило MimoSM, LLM с AI, обученным содержанию ISA. Он дает представление о операционных технологиях (OT) кибербезопасности и промышленной автоматизации, используя стандарты ISA, учебные материалы, технические отчеты и отраслевые публикации.
В июне 2024 года, Tech Mahindra запустил проект Indus, коренной основополагающей большой языковой модели (LLM), поддерживающей несколько индийских языков и диалектов. Начальная фаза посвящена хинди и его 37+ диалектам.
В апреле 2024 года, Snowflake запустил Snowflake Arcct, открытый LLM Enterprise Grade с архитектурой смеси экспертов (MOE). Арктика оптимизирована для сложных рабочих нагрузок предприятия и продемонстрировала ведущую отраслевую производительность в генерации кода SQL, следующих инструкциях и других контрольных показателях.
Часто задаваемые вопросы
Каков ожидаемый CAGR для рынка крупных языковых моделей в течение прогнозируемого периода?
Насколько велика была индустрия в 2023 году?
Каковы основные факторы, способствующие рынку?
Кто является ключевыми игроками на рынке?
Какой регион должен быть самым быстрорастущим на рынке в течение прогнозируемого периода?
Предполагается, что какой сегмент будет иметь самую большую долю рынка в 2031 году?
Автор
Верша имеет более чем 15-летний опыт управления консалтинговыми заданиями в различных отраслях, включая продукты питания и напитки, потребительские товары, ИКТ, аэрокосмическую промышленность и другие. Ее междисциплинарный опыт и способность к адаптации делают ее универсальным и надежным профессионалом. Обладая острыми аналитическими способностями и любопытным мышлением, Верша преуспевает в преобразовании сложных данных в практические идеи. Она имеет успешный опыт определения динамики рынка, выявления тенденций и предоставления индивидуальных решений для удовлетворения потребностей клиентов. Будучи опытным лидером, Верша успешно обучал исследовательские группы и точно руководил проектами, обеспечивая высококачественные результаты. Ее подход к сотрудничеству и стратегическое видение позволяют ей превращать проблемы в возможности и последовательно добиваться впечатляющих результатов. Анализируя рынки, привлекая заинтересованные стороны или разрабатывая стратегии, Верша опирается на свой глубокий опыт и отраслевые знания для стимулирования инноваций и достижения измеримой ценности.
Имея более десяти лет опыта руководства исследованиями на глобальных рынках, Ганапати обладает острым суждением, стратегической ясностью и глубокой отраслевой экспертизой. Известный своей точностью и непоколебимой приверженностью качеству, он направляет команды и клиентов с инсайтами, которые постоянно обеспечивают значимые бизнес-результаты.