Tamanho do mercado de geração de dados sintéticos, participação, crescimento e análise da indústria, por dados (dados tabulares, dados de texto, dados de imagem e vídeo, outros), por aplicação (gerenciamento de dados de teste, treinamento e desenvolvimento de IA, compartilhamento de dados empresariais, análise de dados e visualização), por usuário final (serviços financeiros, varejo, saúde, outros) e análise regional, 2026-2033
Páginas: 180 | Ano base: 2025 | Lançamento: fevereiro de 2026 | Autor: Ashim L. | Última atualização: março de 2026
Dados sintéticos são dados artificiais projetados para imitar dados do mundo real. É gerado artificialmente, mas mantém as propriedades estatísticas dos dados originais a partir dos quais foi gerado. A geração de dados sintéticos pode acontecer em formato tabular, multimídia ou de texto. Dados de texto sintético podem ser úteis para processamento de linguagem natural (PNL). Da mesma forma, os dados tabulares têm aplicações na criação de tabelas de bancos de dados relacionais.
A multimídia sintética inclui imagens, vídeos e outros dados não estruturados, que podem ser cruciais para tarefas de visão computacional, como reconhecimento e classificação de imagens, entre outras. Existem requisitos crescentes de dados em setores como finanças, saúde e varejo. Os dados sintéticos estão ajudando essas organizações, acelerando a inovação em IA e permitindo decisões mais inteligentes.
Mercado de geração de dados sintéticosVisão geral
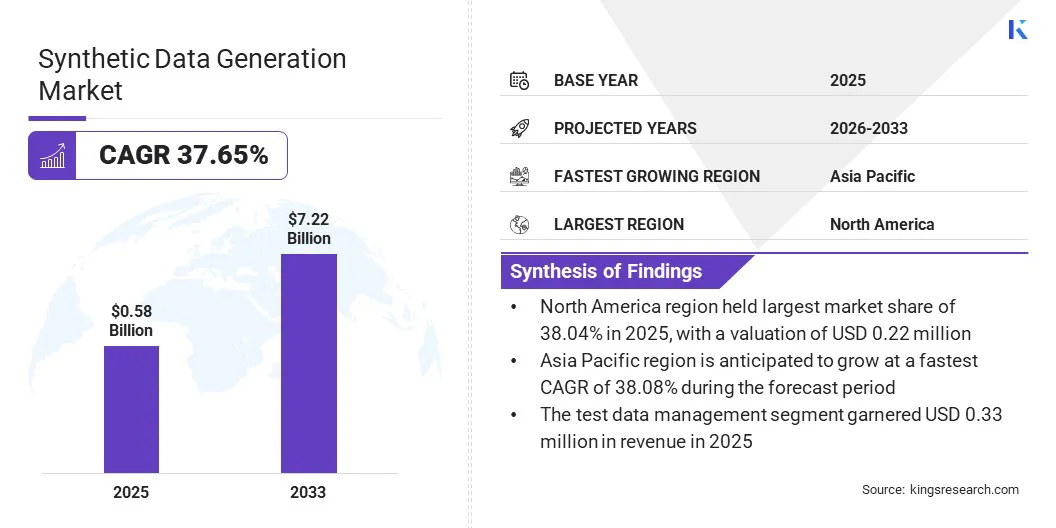
O tamanho do mercado global de geração de dados sintéticos foi avaliado em US$ 0,58 bilhão em 2025 e deve crescer de US$ 0,77 bilhão em 2026 para US$ 7,22 bilhões até 2033, exibindo um CAGR de 37,65% durante o período de previsão. Esse crescimento é atribuído à sua aplicação em sistemas de teste, treinamento de modelos de IA e simulação de cenários, que geralmente são difíceis de capturar em dados reais.
Por exemplo, no sector da saúde, os registos médicos sintéticos podem significar condições como diabetes, doenças ou cancro, o que pode ajudar a desenvolver e testar ferramentas de diagnóstico juntamente com modelos de saúde preditivos.
As principais empresas que operam no mercado global de geração de dados sintéticos são MOSTLY AI, Datagen, TonicAI, Inc., GenRocket, Inc, NVIDIA (Gretel Labs), K2view Ltd, CapGemini (Sogeti), CVEDIA Inc, Microsoft Corporation e MDClone, entre outras.
Espera-se que a procura de dados sintéticos cresça com a sua crescente utilização em vários setores, incluindo o setor automóvel para testes deveículos autônomos, cuidados de saúde para análise de imagens médicas e diagnóstico de pacientes. No setor varejista, é amplamente utilizado para gestão de investimentos e análise do comportamento do cliente.
Pode ser benéfico em finanças para detecção de fraudes e avaliação de riscos. A principal vantagem dos dados sintéticos compreende a relação custo-benefício, escalabilidade e diversidade. Eles são amplamente usados no treinamento de modelos de aprendizado de máquina. Oferece maior controle sobre a qualidade dos dados e também preserva a privacidade, eliminando o uso de dados reais e confidenciais.
A tendência recente indica a integração do aprendizado federado e da privacidade diferencial para aprimorar o aprendizado de máquina que preserva a privacidade. Além disso, a procura por conjuntos de dados de formação diversos e de alta qualidade aumentará com a expansão da IA em novos domínios, tornando os dados sintéticos muito cruciais.
Principais destaques:
O tamanho do mercado global de geração de dados sintéticos foi registrado em US$ 0,58 bilhão em 2025.
O mercado deverá crescer a um CAGR de 37,65% de 2026 a 2033.
A América do Norte detinha uma participação de 38,04% em 2025, avaliada em US$ 0,22 bilhão.
O segmento de dados tabulares obteve receitas de US$ 0,20 bilhões em 2025.
Espera-se que o segmento de gerenciamento de dados de teste atinja US$ 4,05 bilhões até 2033.
Prevê-se que o segmento de saúde testemunhe o CAGR mais rápido de 38,28% durante o período de previsão.
Prevê-se que a Ásia-Pacífico cresça a um CAGR de 38,08% durante o período de projeção.
Quão confiáveis são os dados sintéticos para treinamento de IA?
Os dados sintéticos, quando gerados utilizando técnicas robustas, podem igualar ou, em alguns casos, superar os dados reais no desempenho do modelo, especialmente em cenários de eventos raros.
Embora não possa substituir os dados reais, é muito eficaz no apoio aos dados reais, especialmente quando a equipa lida com dados limitados, conjuntos de dados desequilibrados ou restrições de privacidade. Como resultado, pode funcionar como um complemento poderoso aos dados reais, em vez de um substituto completo.
Em outubro de 2024, a MOSTLY AI revelou sua nova funcionalidade de texto sintético para treinar modelos de IA e também cuida da privacidade de ativos de dados proprietários. Ajuda a organização a usar uma ampla gama de dados de texto, como e-mails, conversas de chatbot, transcrições de suporte ao cliente, etc., para treinar e ajustar omodelos de linguagem grande (LLMs), e não há risco de violação de privacidade.
Porque é que a formação de sistemas de IA exige a consciência de que os dados sintéticos podem criar resultados falsos?
Os dados sintéticos podem não ter a complexidade e as nuances dos dados do mundo real, o que pode fazer com que os modelos de IA tenham um desempenho insatisfatório em cenários do mundo real. Além disso, existe a possibilidade de que os modelos de IA totalmente treinados em dados sintéticos não possam generalizar eficazmente para situações do mundo real devido às disparidades entre os dados sintéticos e reais. Também poderia levantar questões éticas em algumas das aplicações, como o diagnóstico médico.
Como a geração de dados sintéticos oferece vantagens comerciais em termos de custo e escalabilidade?
A coleta real de dados é cara e lenta com a associação de implantação, rotulagem e segurança de sensores. Mas os dados sintéticos para aprendizado de máquina on-line podem ser facilmente gerados de maneira mais barata e rápida. Os dados sintéticos oferecem fontes de dados controladas e escaláveis para o desenvolvimento robusto da IA. Por exemplo, organizações como Nvidia e Databricks oferecem ferramentas como Unity Catalog e Omniverse Replicator para automatizar pipelines de dados sintéticos. Estima-se que cerca de 50% a 60% dos dados utilizados para treinar plataformas de IA sejam sintéticos. A sua procura está a aumentar à medida que ajuda as organizações a simular novos produtos, acelerar o desenvolvimento de modelos de IA e proteger informações sensíveis.
Em outubro de 2025, a GenRocket anunciou o lançamento de seu acelerador de dados não estruturados (UDA), que levou a organização de geração de dados sintéticos orientada ao design a expandir sua plataforma além dos dados estruturados para imagens, documentos e formatos baseados em arquivos. Ajudou a organização a gerar qualquer forma de dados com segurança, precisão e escala sob demanda.
Instantâneo do relatório de mercado de geração de dados sintéticos
Segmentação
Detalhes
Por dados
Dados tabulares, dados de texto, dados de imagem e vídeo, outros
Por aplicativo
Gerenciamento de dados de teste, treinamento e desenvolvimento de IA, compartilhamento de dados empresariais, análise e visualização de dados
Por usuário final
Serviços Financeiros, Varejo, Saúde e Outros
Por região
América do Norte: EUA, Canadá, México
Europa: França, Reino Unido, Espanha, Alemanha, Itália, Rússia, Resto da Europa
Ásia-Pacífico: China, Japão, Índia, Austrália, ASEAN, Coreia do Sul, Resto da Ásia-Pacífico
Oriente Médio e África: Turquia, Emirados Árabes Unidos, Arábia Saudita, África do Sul, Resto do Médio Oriente e África
Ámérica do Sul: Brasil, Argentina, Resto da América do Sul
Segmentação de Mercado
Por dados (dados tabulares, dados de texto, dados de imagem e vídeo e outros): O segmento de dados tabulares gerou US$ 0,20 bilhão em receitas em 2025, principalmente devido à sua crescente adoção nos setores de comércio eletrônico e saúde. É amplamente usado para treinar de forma eficaz alguns modelos de aprendizado de máquina.
Por aplicação (gerenciamento de dados de teste, treinamento e desenvolvimento de IA, compartilhamento de dados empresariais e análise e visualização de dados): O segmento de treinamento e desenvolvimento de IA está preparado para registrar um CAGR impressionante de 38,08% durante o período de previsão, impulsionado por sua ampla exigência no treinamento de modelos de aprendizado de máquina. Ele está servindo como uma solução potencial para cenários onde há necessidade de dados, mas há escassez de dados do mundo real de alta qualidade para treinar modelos de IA.
Por usuário final (serviços financeiros, varejo, saúde e outros): Estima-se que o segmento de serviços financeiros detenha uma participação de 32,13% até 2032, alimentado pelas vantagens dos dados sintéticos, como compartilhamento seguro de dados e desenvolvimento de modelos para avaliação de risco, detecção de fraude e análise sem expor as informações reais do cliente. A geração de dados sintéticos pode ser possível para eventos raros, como quebras de mercado ou formas complexas de fraude, o que ajuda a melhorar o desempenho do modelo e a acelerar o desenvolvimento da IA.
Qual é o cenário do mercado na América do Norte e na região Ásia-Pacífico?
Com base na região, o mercado global de geração de dados sintéticos foi classificado na América do Norte, Europa, Ásia-Pacífico, Oriente Médio e África e América do Sul.
O mercado de geração de dados sintéticos da América do Norte representou uma participação de 38,04% em 2025, avaliado em US$ 0,22 bilhão. Este domínio é atribuído a uma combinação de infra-estruturas tecnológicas avançadas e mais investimento em I&D na região. Nos EUA, em particular, as empresas estão a adoptar as tecnologias mais recentes para diminuir os riscos e a ineficiência.
Além disso, os consumidores preferem apoiar marcas que se concentrem em inovações incrementais. No retalho, a geração de dados sintéticos está a ajudar a analisar as preferências dos clientes, tais como hábitos de compra e procura sazonal, ao mesmo tempo que protege a privacidade. A região tem obrigações crescentes de privacidade de dados e um forte ecossistema de IA, que está a criar um ambiente favorável para o crescimento do mercado.
Em junho de 2021, a CVEDIA anunciou uma solução para a lacuna de adoção de domínios usando o pipeline de dados sintéticos proprietário. Eles podem ajudar no desenvolvimento da IA, permitindo que algoritmos treinados em dados sintéticos funcionem junto com aqueles treinados em dados reais. A CVEDIA afirmou uma melhoria na precisão de 170% e sustentou um ganho de 160% no recall em comparação com os modelos de referência.
O mercado de geração de dados sintéticos da Ásia-Pacífico deverá crescer a um CAGR de 38,08% durante o período de previsão. Este crescimento notável é apoiado pela utilização crescente de dados sintéticos em vários domínios da região, como saúde, indústria transformadora, etc.
Por exemplo, na área da saúde, os dados sintéticos são gerados para a criação de registos realistas de pacientes, que ajudam na investigação, ao mesmo tempo que oferecem anonimização e agregação. Ajuda os pesquisadores médicos a desenvolver e testar algoritmos para diagnóstico e tratamento, ao mesmo tempo que segue os rígidos regulamentos de proteção de dados.
Na indústria, as empresas automóveis estão a utilizar dados sintéticos para simular uma série de cenários de condução para os carros autónomos. Ajuda no treinamento de modelos de aprendizado de máquina para reconhecer e responder a diversas condições sem a necessidade de uma extensa coleta de dados do mundo real. Empresas como Waymo e Tesla estão revolucionando o uso de dados sintéticos para treinar seus carros autônomos.
Marcos Regulatórios
O Regulamento Geral de Proteção de Dados (GDPR) controla o processamento de dados pessoais na UE e define o que se qualifica como dados anonimizados ou sintéticos.
A Lei de Dados (Uso e Acesso) de 2025 no Reino Unido cuida das disposições relacionadas ao processamento e acesso de dados pessoais e comerciais. Ele atualiza a estrutura existente do GDPR e da Lei de Proteção de Dados do Reino Unido.
Nos Estados Unidos (Califórnia), a Lei de Privacidade do Consumidor da Califórnia (CCPA) e sua alteração, a Lei de Direitos de Privacidade da Califórnia (CPRA) regem a coleta e o uso de dados pessoais.
Cenário Competitivo
Os principais players do mercado de geração de dados sintéticos estão focando principalmente na inovação tecnológica contínua. Existem muitos pequenos e médios players que visam tipos e setores de dados específicos. Os fornecedores especializados não detêm uma participação dominante no mercado e operam em segmentos de nicho.
Grandes plataformas de nuvem e IA, como Microsoft e NVIDIA, entre outras, têm uma parcela importante no mercado, pois os recursos de dados sintéticos estão presentes em serviços mais amplos de IA e ML. O foco também está em parcerias e aquisições para obter vantagens estratégicas.
Em março de 2025, a Nvidia adquiriu a Gretel, uma startup de dados sintéticos, por mais de US$ 320 milhões, o que está ajudando seu conjunto de serviços generativos de IA para desenvolvedores. Gretel mantém parcerias com grandes provedores de nuvem, como Google Cloud, Amazon Web Services e Microsoft.
Principais empresas no mercado de geração de dados sintéticos:
Em abril de 2023, a MDClone anunciou que a sua plataforma ADAMS está a permitir um maior número de parcerias entre organizações prestadoras de cuidados de saúde e empresas de ciências da vida para acelerar a investigação e desenvolvimento terapêutico.
Perguntas frequentes
Quais são os principais impulsionadores do mercado de geração de dados sintéticos?
Quais regiões são centrais para o crescimento da geração de dados sintéticos?
Que desafios a indústria de geração de dados sintéticos enfrenta hoje?
Que tendências estão moldando o futuro da geração de dados sintéticos?
Quem são os principais players deste setor?
Que oportunidades existem para investidores?
Como é que este relatório me ajuda a concentrar a nossa estratégia de crescimento na região geográfica mais promissora?
Como este relatório me ajuda a entender qual categoria de DADOS tem o maior impacto econômico?
Autor
Ashim supervisiona compromissos de inteligência de mercado sindicalizados e personalizados, desde o design até a entrega. Ele é especialista em inteligência de mercado, modelagem de crescimento, estratégia competitiva e suporte a decisões executivas. Sua abordagem de liderança enfatiza a clareza de pensamento e o impacto mensurável nos negócios.
Com mais de uma década de liderança em pesquisa em mercados globais, Ganapathy traz julgamento aguçado, clareza estratégica e profunda expertise na indústria. Conhecido por sua precisão e compromisso inabalável com a qualidade, ele orienta equipes e clientes com insights que impulsionam consistentemente resultados empresariais impactantes.