


合成データ生成市場
合成データ生成市場規模、シェア、成長および業界分析、データ別(表形式データ、テキストデータ、画像およびビデオデータ、その他)、アプリケーション別(テストデータ管理、AIトレーニングおよび開発、エンタープライズデータ共有、データ分析および視覚化)、エンドユーザー別(金融サービス、小売、ヘルスケア、その他)、および地域分析、 2026-2033
ページ: 180 | 基準年: 2025 | リリース: 2026年2月 | 著者: Ashim L. | 最終更新: 2026年3月
今すぐお問い合わせ
ページ: 180 | 基準年: 2025 | リリース: 2026年2月 | 著者: Ashim L. | 最終更新: 2026年3月
合成データは、現実世界のデータを模倣するように設計された人工データです。これは人工的に生成されますが、生成元の元のデータの統計的特性が保持されます。合成データの生成は、表形式、マルチメディア形式、またはテキスト形式で行うことができます。合成テキスト データは、自然言語処理 (NLP) に役立ちます。同様に、表形式のデータはリレーショナル データベース テーブルの作成に応用できます。
合成マルチメディアには、画像、ビデオ、その他の非構造化データが含まれます。これらは、特に画像認識や画像分類などのコンピューター ビジョン タスクにとって重要となる可能性があります。金融、ヘルスケア、小売などの分野ではデータ要件が高まっています。合成データは、AI イノベーションを加速し、より賢明な意思決定を可能にすることで、このような組織を支援しています。
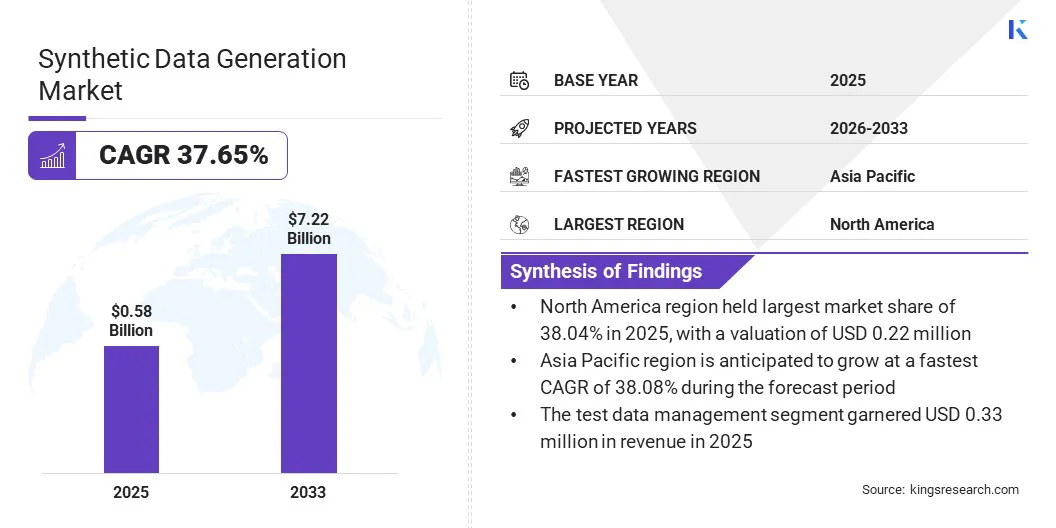
世界の合成データ生成市場規模は、2025年に5.8億米ドルと評価され、2026年の7.7億米ドルから2033年までに72.2億米ドルに成長すると予測されており、予測期間中に37.65%のCAGRを示します。この成長は、テスト システム、AI モデルのトレーニング、および実際のデータでキャプチャするのが一般的に難しいシナリオのシミュレーションへのアプリケーションに起因しています。
たとえば、ヘルスケア分野では、合成医療記録は糖尿病、病気、がんなどの状態を示すことができ、予測健康モデルとともに診断ツールの開発とテストに役立ちます。
世界の合成データ生成市場で活動している主要企業は、MOSTLY AI、Datagen、TonicAI, Inc.、GenRocket, Inc、NVIDIA (Gretel Labs)、K2view Ltd、CapGemini (Sogeti)、CVEDIA Inc、Microsoft Corporation、MDClone などです。
合成データの需要は、データのテストのための自動車分野を含むいくつかの分野での使用の増加に伴い成長すると予想されます。自動運転車、医療画像解析および患者診断のためのヘルスケア。小売部門では、投資管理や顧客行動分析に主に使用されています。
金融業界では、不正行為の検出とリスク評価に役立ちます。合成データの主な利点には、費用対効果、拡張性、多様性が含まれます。これらは主に、機械学習モデルのトレーニングに使用されます。 データ品質をより細かく制御できるほか、実際の機密データの使用を排除することでプライバシーも保護されます。
最近の傾向は、プライバシー保護機械学習を強化するために、フェデレーテッド ラーニングと差分プライバシーを統合することを示しています。また、新しい領域での AI の拡大に伴い、多様で高品質のトレーニング データセットに対する需要が高まるため、合成データが非常に重要になります。
合成データは、堅牢な技術を使用して生成された場合、特にまれなイベントのシナリオにおいて、モデルのパフォーマンスにおいて実際のデータと同等、または場合によってはそれを上回る可能性があります。
実際のデータを置き換えることはできませんが、実際のデータをサポートする場合、特にチームが限られたデータ、不均衡なデータセット、またはプライバシーの制約を扱う場合には非常に効果的です。その結果、完全に置き換えるのではなく、実際のデータを強力に補完するものとして機能します。
合成データには現実世界のデータの複雑さやニュアンスが欠けている可能性があり、そのため現実世界のシナリオでは AI モデルのパフォーマンスが低下する可能性があります。さらに、合成データで完全にトレーニングされた AI モデルは、合成データと実際のデータの間に差異があるため、現実世界の状況に効果的に一般化できない可能性があります。また、医療診断などの一部のアプリケーションでは倫理的な懸念が生じる可能性もあります。
実際のデータ収集は、センサーの導入、ラベル付け、セキュリティに関連するため、コストがかかり、時間がかかります。 しかし、オンライン機械学習用の合成データは、より安価かつ迅速に簡単に生成できます。合成データは、AI の堅牢な開発のための、制御されたスケーラブルなデータ ソースを提供します。たとえば、Nvidia や Databricks などの組織は、合成データ パイプラインを自動化するための Unity Catalog や Omniverse Replicator などのツールを提供しています。 AI プラットフォームのトレーニングに使用されるデータの約 50% ~ 60% は合成データであると推定されています。組織が新製品をシミュレーションし、AI モデル開発を加速し、機密情報を保護するのに役立つため、その需要が高まっています。
|
セグメンテーション |
詳細 |
|
データ別 |
表形式データ、テキストデータ、画像・動画データ、その他 |
|
用途別 |
テストデータ管理、AI トレーニングと開発、エンタープライズ データ共有、データ分析と視覚化 |
|
エンドユーザー別 |
金融サービス、小売、ヘルスケア、その他 |
|
地域別 |
北米:アメリカ、カナダ、メキシコ |
|
ヨーロッパ: フランス、イギリス、スペイン、ドイツ、イタリア、ロシア、その他のヨーロッパ | |
|
アジア太平洋地域: 中国、日本、インド、オーストラリア、ASEAN、韓国、その他のアジア太平洋地域 | |
|
中東とアフリカ: トルコ、アラブ首長国連邦、サウジアラビア、南アフリカ、その他の中東およびアフリカ | |
|
南アメリカ: ブラジル、アルゼンチン、その他の南米 |
世界の合成データ生成市場は、地域に基づいて、北米、ヨーロッパ、アジア太平洋、中東およびアフリカ、南米に分類されています。

北米の合成データ生成市場は、2025 年に 38.04% のシェアを占め、その価値は 22 億米ドルに達しました。この優位性は、先進的な技術インフラとこの地域での研究開発へのさらなる投資の組み合わせによるものです。 特に米国では、リスクと非効率を軽減するために企業が最新テクノロジーを導入しています。
さらに、消費者は漸進的なイノベーションに重点を置くブランドを支持することを好みます。 小売業界では、合成データの生成は、プライバシーを保護しながら、買い物習慣や季節的な需要などの顧客の好みの分析に役立ちます。この地域にはデータプライバシーの義務が増大しており、強力なAIエコシステムがあり、市場の成長に好ましい環境を生み出しています。
アジア太平洋地域の合成データ生成市場は、予測期間中に 38.08% の CAGR で成長すると予測されています。この顕著な成長は、医療、製造など、この地域のいくつかの分野での合成データの使用の増加によって支えられています。
たとえば、医療分野では、現実的な患者記録を作成するために合成データが生成され、匿名化と集約を提供しながら研究に役立ちます。医療研究者が厳格なデータ保護規制に従いながら、診断と治療のためのアルゴリズムを開発およびテストするのに役立ちます。
製造業では、自動車会社は合成データを使用して自動運転車のさまざまな運転シナリオをシミュレートしています。これは、現実世界の大規模なデータ収集を必要とせずに、いくつかの条件を認識して対応するための機械学習モデルをトレーニングするのに役立ちます。 Waymo や Tesla などの企業は、自動運転車のトレーニングのための合成データの使用に革命を起こしています。
合成データ生成市場の主要企業は主に継続的な技術革新に重点を置いています。特定のデータ タイプやセクターをターゲットとする小規模プレーヤーや中規模プレーヤーが多数存在します。専門ベンダーは圧倒的な市場シェアを保持しておらず、ニッチなセグメントで事業を展開しています。
Microsoft や NVIDIA などの大手クラウドおよび AI プラットフォームは、より広範な AI および ML サービス内に合成データ機能が存在するため、市場で重要な役割を果たしています。戦略的優位性を実現するためのパートナーシップや買収にも焦点が当てられています。
よくある質問