


大規模な言語モデル市場
大規模な言語モデル市場規模、シェア、成長、業界分析、タイプ別(ドメイン固有、汎用、多言語、多言語)、モダリティ(テキスト、画像、オーディオ)、アーキテクチャ(自己回帰、自動エンコード)、アプリケーション、業界の垂直および地域分析、 2024-2031
ページ: 230 | 基準年: 2023 | リリース: 2025年4月 | 著者: Versha V. | 最終更新: 2026年2月
今すぐお問い合わせ
ページ: 230 | 基準年: 2023 | リリース: 2025年4月 | 著者: Versha V. | 最終更新: 2026年2月
市場には、自然言語加工(NLP)の高度な人工知能モデルの開発、展開、および商業化が含まれます。
LLMの研究、トレーニング、および最適化に従事する企業と、APIおよびエンタープライズプラットフォームを通じてLLMベースのソリューションを提供するクラウドサービスプロバイダーが含まれます。さらに、市場は、チャットボット、コンテンツ生成、コード開発などのアプリケーションにLLMを採用している業界に及びます。
世界の大規模な言語モデルの市場規模は2023年に59億4,000万米ドルと評価され、2024年の77億3,000万米ドルから2031年までに60.07億米ドルに成長すると予測されており、予測期間中に34.03%のCAGRを示しています。
市場の成長は、テクノロジー、ヘルスケア、財務、小売、顧客サービスなどの多様な業界全体での採用の増加によって推進されています。 AI駆動型の自動化に対する需要の高まりが強化されました会話AI、および高度なデータ分析機能は、LLMの研究開発への投資を促進しています。
大規模な言語モデル業界で事業を展開している大手企業は、Microsoft、Mistral AI、Stability AI Ltd、IBM、AI21 Labs、Ai21 Labs、Google、Eleutherai、G42、Alibaba、Amazon.com、Inc.、Deepseek、Meta、Coheer、およびLightonです。
LLMのビジネスワークフロー、コンテンツの作成、ソフトウェア開発への統合により、商業的可能性が拡大しています。 AIのイノベーションをサポートする戦略的パートナーシップ、合併、政府のイニシアチブは、市場の成長をさらに高め、LLMをグローバルAIランドスケープの重要な要素として位置づけています。

マーケットドライバー
「企業の採用とAIの進歩」
大規模な言語モデル(LLMS)市場は、AIインフラストラクチャの企業の採用と進歩の増加に牽引されて、急速な成長を遂げています。金融、ヘルスケア、eコマース、顧客サービスなど、さまざまな業界の企業がLLMを活用して、自動化を強化し、顧客エンゲージメントを改善し、データ分析を合理化しています。
LLMが人間のようなテキストを生成し、意思決定を支援し、ユーザーエクスペリエンスをパーソナライズする能力により、デジタル変換のための貴重なツールになりました。
さらに、AIインフラストラクチャとコンピューティングパワーの進歩は、市場の拡大をサポートしています。高性能コンピューティング(HPC)リソース、クラウドベースのAIプラットフォーム、および特殊なAIチップ(GPUやTPUなど)の進歩により、LLMSのトレーニングと展開の効率が向上しました。これらの革新により、より強力でスケーラブルなモデルの開発が可能になり、採用と商業的実行可能性が高まります。
市場の課題
「高い計算コストとエネルギー消費」
大規模な言語モデル(LLMS)市場の拡大を妨げる主要な課題は、トレーニングと展開に必要な高い計算コストとエネルギー消費です。 LLMは、膨大なデータセットと高性能コンピューティングリソースに依存しており、実質的なインフラ費用と二酸化炭素排出量の増加につながります。
GPUやTPUなどの特殊なハードウェアへの依存により、コストがさらに引き上げられ、小規模企業のアクセシビリティが制限されます。この課題は、クエリあたりのモデルのパラメーターのほんの一部のみをアクティブにして計算需要を減らすために、混合物(MOE)モデルなど、より効率的なモデルアーキテクチャの開発を通じて対処できます。
市場動向
「マルチモーダル機能とオープンソースのイノベーション」
大規模な言語モデル(LLMS)市場は、マルチモーダルLLMの台頭とオープンソースの拡大に促進された大幅な拡大を目撃しています。テキスト、画像、オーディオ、ビデオを処理できるマルチモーダルLLMは、コンテンツ作成、ヘルスケア診断、およびインタラクティブAIで注目を集めています。これらのモデルは、より豊かでよりコンテキスト的な応答を提供し、商業的価値を高めることにより、ユーザーのエンゲージメントを強化します。
さらに、オープンソースLLMSの拡大は、イノベーションとアクセシビリティを促進しています。企業や研究機関は、オープンソースモデルをますますリリースしているため、開発者は特定のアプリケーション向けにカスタマイズおよび最適化できるようになりました。
この傾向はAIを民主化し、企業、スタートアップ、研究者が独自のソリューションのみに依存することなく高度なLLMを活用できるようにし、グローバルなAIの進歩を加速させます。
|
セグメンテーション |
詳細 |
|
タイプごとに |
ドメイン固有、汎用、多言語 |
|
モダリティによって |
テキスト、画像、オーディオ、ビデオ |
|
アーキテクチャによる |
自己回帰、自動エンコード、ハイブリッド |
|
アプリケーションによって |
チャットボットと仮想アシスタント、コード生成、コンテンツ生成、カスタマーサービス、言語翻訳、センチメント分析 |
|
業界の垂直によって |
ヘルスケア、BFSI、教育、メディア、エンターテイメント、その他 |
|
地域別 |
北米:米国、カナダ、メキシコ |
|
ヨーロッパ:フランス、英国、スペイン、ドイツ、イタリア、ロシア、ヨーロッパのその他 | |
|
アジア太平洋:中国、日本、インド、オーストラリア、ASEAN、韓国、アジア太平洋地域の残り | |
|
中東とアフリカ:トルコ、アラブ首長国連邦、サウジアラビア、南アフリカ、中東の残りのアフリカ | |
|
南アメリカ:ブラジル、アルゼンチン、南アメリカの残り |
市場セグメンテーション
大規模な言語モデル市場地域分析
地域に基づいて、市場は北米、ヨーロッパ、アジア太平洋、中東、アフリカ、ラテンアメリカに分類されています。
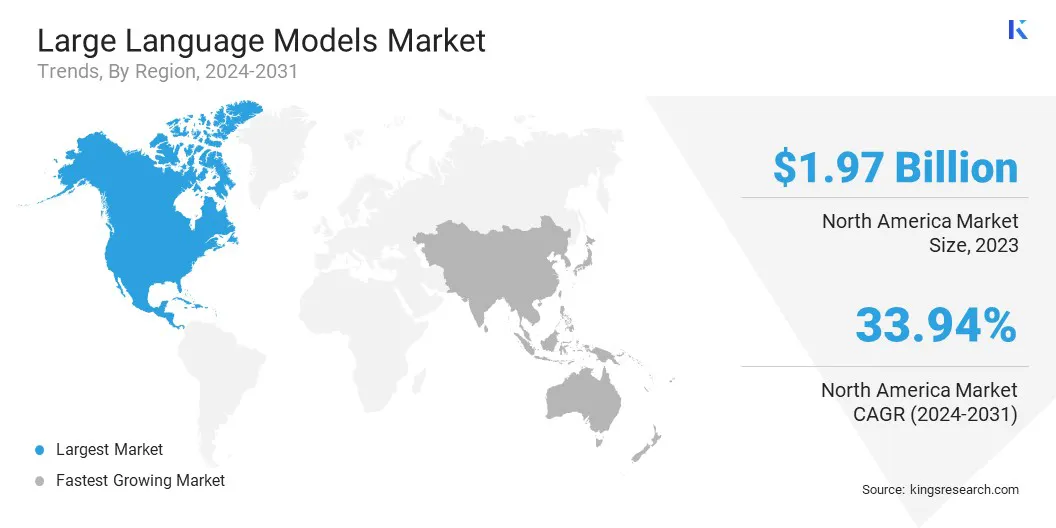
北米の大規模な言語モデルの市場シェアは、2023年に約33.24%であり、19億7000万米ドルの価値がありました。この優位性は、大手AIの調査会社、Google、Microsoft、Metaなどのハイテク大手、およびAIインフラストラクチャへの多額の投資によって強化されています。クラウドコンピューティング。
地域市場は、AIの進歩、堅牢な新興企業のエコシステム、および金融、ヘルスケア、顧客サービス全体のLLMの広範な企業採用のための強力な政府および民間部門の資金からさらに利益を得ています。
さらに、北米の高度な半導体およびコンピューティングハードウェア業界、特に米国では、LLMの開発と展開を加速し、地域市場の拡大を支援しています。
アジア太平洋言語モデル産業は、予測期間にわたって35.10%のかなりのCAGRで成長する態勢を整えています。この成長は、AIの研究への投資、デジタル変革を促進する政府のイニシアチブ、および教育、eコマース、通信などの業界全体でAI主導の自動化の需要の増加によって促進されます。
この地域のいくつかの政府は、資金調達プログラム、国家AI戦略、およびインフラの改善を通じてAI開発を積極的に支援しています。各国は、AIの研究ハブを設立し、学界と産業の協力を促進し、公共サービスおよび企業でのAIの採用を促進するためのポリシーを実施しています。
さらに、大規模なインターネットユーザーベース、多言語の多様性、およびデータエコシステムの増加により、ローカル言語やアプリケーションに合わせたLLMSの需要が高まります。高性能コンピューティングの拡張を含むAIインフラストラクチャの強化により、企業部門と消費者の両方のセクターの両方での採用がさらに加速されます。
大規模な言語モデル業界の主要なプレーヤーは、市場の地位を強化するために、技術の進歩、戦略的パートナーシップ、および大規模なインフラストラクチャ投資に焦点を当てています。
彼らは、トレーニングと微調整の独自のLLMに多額の投資を行っており、モデルの精度、効率、および文脈の理解を改善するために広範なデータセットを活用しています。
主要な競争戦略には、クラウドベースのAIサービス、LLMSをエンタープライズアプリケーションに統合し、ヘルスケア、ファイナンス、カスタマーサービスなどの業界でAPIおよびカスタマイズされたAIソリューションを提供します。
さらに、企業はマルチモーダル機能を拡大し、テキストを超えてLLMを拡張して画像、オーディオ、ビデオ処理を含めてユーザーの相互作用を強化し、アプリケーションスコープを拡大しています。
学術機関、AIリサーチラボ、クラウドプロバイダーとの戦略的コラボレーションは、イノベーションを加速しています。企業は、商業化のための独自のモデルを維持しながら、開発者の関与を促進するためにオープンソースのフレームワークを活用しています。
競争が激化するにつれて、市場は地域固有のLLMへの移行を目撃して、地元の言語や文化的文脈をサポートしています。さらに、Edge AIおよびDevice処理の進歩により、レイテンシが低く、プライバシーが強化されたLLM機能が向上しています。
最近の開発(パートナーシップ/新製品の発売)
よくある質問