Marktgröße, Anteil, Wachstum und Branchenanalyse für Bildverarbeitungstransformatoren, nach Angebot (Lösung, Dienstleistungen), nach Anwendung (Bildklassifizierung, Bildunterschrift, Bildsegmentierung, andere), nach Endverbrauchsbranche (Gesundheitswesen und Biowissenschaften, Einzelhandel und E-Commerce, Automobil, Regierung und Verteidigung, andere) und regionale Analyse, 2024-2031
Seiten: 160 | Basisjahr: 2023 | Veröffentlichung: März 2025 | Autor: Sharmishtha M. | Zuletzt aktualisiert: Februar 2026
Der Markt umfasst die Entwicklung und Anwendung von Vision Transformer-Modellen für die Bild- und Videoverarbeitung. ViTs zeichnen sich durch die Erfassung weitreichender Abhängigkeiten und Kontextbeziehungen aus und eignen sich daher für die Bildklassifizierung, Objekterkennung und das Szenenverständnis. Ihre Fähigkeiten treiben Fortschritte bei KI-gestützten Computer-Vision-Anwendungen in verschiedenen Branchen voran.
Markt für Vision-TransformatorenÜberblick
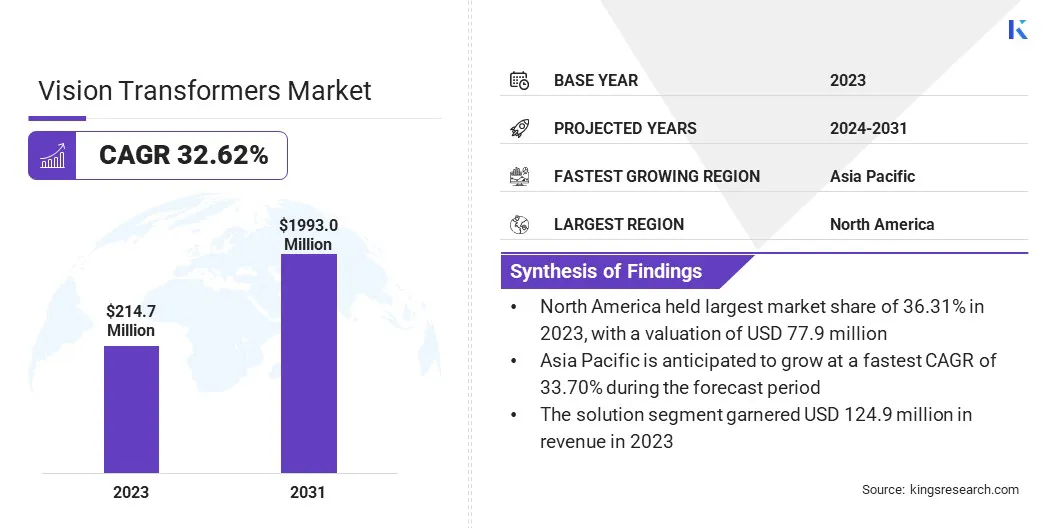
Die weltweite Marktgröße für Vision-Transformatoren wurde im Jahr 2023 auf 214,7 Millionen US-Dollar geschätzt, was im Jahr 2024 auf 276,3 Millionen US-Dollar geschätzt wird und bis 2031 1.993,0 Millionen US-Dollar erreichen wird, was einem durchschnittlichen jährlichen Wachstum von 32,62 % von 2024 bis 2031 entspricht.
Überragende Leistung bei komplexen Aufgaben wie Bilderkennung und Verarbeitung natürlicher Sprache treibt das Wachstum des Marktes voran, indem sie im Vergleich zu herkömmlichen Methoden eine höhere Genauigkeit, Skalierbarkeit und Effizienz bietet.
Zu den wichtigsten Unternehmen, die in der Vision-Transformator-Branche tätig sind, gehören Google LLC, OpenAI OpCo, LLC, Meta, NVIDIA Corporation, LeewayHertz, Microsoft, Qualcomm Technologies, Inc., viso.ai, Clarifai, Inc., QUADRIC, Datature, Apple Inc., Innova Solutions, V7 Ltd, Ultralytics Inc und andere.
Der Markt hat sich schnell weiterentwickelt und sich zu einem wichtigen Akteur im Bereich Computer Vision entwickelt. Ihre Stärke liegt in der Erfassung langfristiger Abhängigkeiten und bietet eine größere Flexibilität und Skalierbarkeit als herkömmliche Modelle.
Durch kontinuierliche Fortschritte bei Deep-Learning- und KI-Technologien gewinnen ViTs in der Gesundheits-, Automobil- und Sicherheitsbranche an Bedeutung. Da die Nachfrage nach hochpräzisen Echtzeit-Bildverarbeitungslösungen steigt, werden ViTs zur bevorzugten Wahl für KI-gesteuerte Bildverarbeitungslösungen.
Im Januar 2024 optimierte Apples Forschung Vision Transformer (ViTs) für die Apple Neural Engine (ANE), wodurch die Verarbeitungsgeschwindigkeit verbessert und die Latenz reduziert wurde. Innovationen wie lokale Aufmerksamkeitsblöcke, alternative Positionseinbettungen und effiziente Tensorpartitionierung verbesserten die ViT-Leistung und kamen Anwendungen wie der Bildklassifizierung und der Objektsegmentierung zugute.
Wichtigste Highlights:
Die Größe der Vision-Transformatoren-Branche belief sich im Jahr 2023 auf 214,7 Millionen US-Dollar.
Der Markt soll von 2024 bis 2031 mit einer jährlichen Wachstumsrate von 32,62 % wachsen.
Nordamerika hatte im Jahr 2023 einen Anteil von 36,31 % im Wert von 77,9 Mio. USD.
Das Lösungssegment erzielte im Jahr 2023 einen Umsatz von 124,9 Millionen US-Dollar.
Das Bildklassifizierungssegment wird bis 2031 voraussichtlich 668,9 Millionen US-Dollar erreichen.
Das Segment Gesundheitswesen und Biowissenschaften wird im Prognosezeitraum voraussichtlich die schnellste CAGR von 34,41 % verzeichnen
Der asiatisch-pazifische Raum wird im Prognosezeitraum voraussichtlich mit einer jährlichen Wachstumsrate von 33,70 % wachsen.
Markttreiber
„Überlegene Leistung bei komplexen Aufgaben“
Die Fähigkeit von ViTs, bei komplexen Computer-Vision-Aufgaben eine höhere Genauigkeit zu erreichen, treibt das Wachstum des Marktes für Vision-Transformatoren voran. ViTs erfassen effektiv globale Beziehungen innerhalb eines Bildes, während CNNs hauptsächlich lokale Muster wie Kanten und Texturen erkennen.
Diese Fähigkeit ermöglicht es ViTs, komplexe visuelle Daten effizienter zu verarbeiten, was zu ihrer breiten Akzeptanz in verschiedenen Branchen führt.
Im Mai 2024 brachte Datature seine erste Welle von Vision Transformern für benutzerdefiniertes Modelltraining und die Feinabstimmung der semantischen Segmentierung auf den Markt: Mask2Former und SegFormer. Diese Modelle und ihre Varianten setzen neue Maßstäbe in der semantischen Segmentierungsleistung.
Marktherausforderung
„Speicherbeschränkungen“
Speicherbeschränkungen stellen eine erhebliche Herausforderung für das Wachstum des Marktes für Bildverarbeitungstransformatoren dar, insbesondere bei großen Modellen, die hochauflösende Daten verarbeiten. Diese Modelle erfordern erheblichen Speicher für die Verarbeitung mehrerer Token und Schichten, wodurch die Bereitstellung auf Geräten mit eingeschränkten Ressourcen eingeschränkt wird.
Um dieser Herausforderung zu begegnen, verbessern Techniken wie lokale Aufmerksamkeit, die Bilder in kleinere Segmente aufteilt, und optimierte Tensor-Layouts die Speichereffizienz, verkürzen die Verarbeitungszeit und ermöglichen eine nahtlose Bereitstellung bei gleichzeitiger Beibehaltung der Genauigkeit auf verschiedenen Geräten.
Markttrend
„Expansion in spezialisierte Anwendungen“
Die Ausweitung von ViT auf spezialisierte Domänen wie zdigitale Pathologieentwickelt sich zu einem bemerkenswerten Trend auf dem Markt für Bildtransformatoren. Diese fortschrittlichen Modelle werden für die Präzisionsdiagnostik eingesetzt und verbessern die Genauigkeit der Bildanalyse in Anwendungen wie der Tumorerkennung und -klassifizierung.
Durch die Verarbeitung großformatiger, hochauflösender medizinischer Bilder erlebt der Markt einen Wandel hin zu effizienten, automatisierten Systemen, die die Gesundheitsversorgung und die Patientenergebnisse verbessern.
Im Mai 2024 brachte Microsoft GigaPath auf den Markt, einen spezialisierten Vision Transformer für die digitale Pathologie. Prov-GigaPath wurde in Zusammenarbeit mit dem Providence Health System und der University of Washington entwickelt und ist darauf ausgelegt, Bilder ganzer Objektträger zu analysieren und so die Krebsdiagnose zu verbessern. Mit seiner fortschrittlichen Leistung bei Krebs-Subtypisierungs- und Pathomik-Aufgaben zielt es darauf ab, die Präzisionsgesundheitsversorgung zu transformieren.
Schnappschuss des Vision Transformers-Marktberichts
Segmentierung
Einzelheiten
Durch Anbieten
Lösung (Hardware, Software), Services (Beratung, Bereitstellung und Integration, Schulung, Support und Wartung)
Auf Antrag
Bildklassifizierung, Bildunterschrift, Bildsegmentierung, Objekterkennung und andere
Nach Endverbrauchsindustrie
Gesundheitswesen und Biowissenschaften, Einzelhandel und E-Commerce, Automobil, Regierung und Verteidigung, Sonstiges
Nach Region
Nordamerika: USA, Kanada, Mexiko
Europa: Frankreich, Großbritannien, Spanien, Deutschland, Italien, Russland, übriges Europa
Nach Angebot (Lösung und Dienstleistungen): Das Lösungssegment erzielte im Jahr 2023 aufgrund der steigenden Nachfrage nach schnelleren und effizienteren Bilderkennungstechnologien einen Umsatz von 124,9 Millionen US-Dollar.
Nach Anwendung (Bildklassifizierung, Bildunterschrift, Bildsegmentierung, Objekterkennung und andere): Das Bildklassifizierungssegment hatte im Jahr 2023 einen Anteil von 32,42 %, angetrieben durch Fortschritte bei automatisierten und skalierbaren visuellen Erkennungssystemen.
Nach Endverbrauchsbranche (Gesundheitswesen und Biowissenschaften, Einzelhandel und E-Commerce, Automobil, Regierung und Verteidigung und andere): Das Segment Gesundheitswesen und Biowissenschaften wird bis 2031 voraussichtlich 783,7 Millionen US-Dollar erreichen, angetrieben durch die zunehmende Einführung von Sehtransformatoren in der medizinischen Bildanalyse und Diagnostik.
Markt für Vision-TransformatorenRegionale Analyse
Basierend auf der Region wurde der Markt in Nordamerika, Europa, den asiatisch-pazifischen Raum, den Nahen Osten und Afrika sowie Lateinamerika unterteilt.
Der Marktanteil von Vision-Transformatoren in Nordamerika lag im Jahr 2023 bei rund 36,31 % und wird auf 77,9 Millionen US-Dollar geschätzt. Diese Dominanz wird durch die starke Präsenz von Technologiegiganten, Forschungseinrichtungen und fortschrittlicher Gesundheitsinfrastruktur verstärkt.
Die USA und Kanada sind führend bei der Einführung modernster KI-Technologien, einschließlich Sehtransformatoren, in Bereichen wie der digitalen Pathologie, der Bildgebung im Gesundheitswesen und der Spielebranche. InGamingVision Transformer verbessern die Bildqualität und -stabilität und tragen zu erheblichen Fortschritten bei der KI-gesteuerten Leistung und dem Realismus bei.
Im Januar 2025 stellte NVIDIA auf der CES 2025 DLSS 4 mit Multi Frame Generation vor, das auf einem auf Vision Transformer basierenden KI-Modell basiert. Dieses Upgrade verbessert die Bildqualität, reduziert Geisterbilder und verbessert die Stabilität und bietet eine bis zu 8-fache Leistungssteigerung auf GPUs der GeForce RTX 50-Serie.
Die Branche der Vision-Transformatoren im asiatisch-pazifischen Raum wird im Prognosezeitraum voraussichtlich mit einer robusten jährlichen Wachstumsrate von 33,70 % wachsen. Dieses schnelle Wachstum wird durch Fortschritte bei KI und Gesundheitstechnologien in Ländern wie China, Japan und Indien vorangetrieben.
Der zunehmende Fokus auf Präzisionsmedizin und digitale Gesundheit führt in Verbindung mit wachsenden Investitionen in die KI-Infrastruktur zu einer starken Nachfrage nach Sehtransformatoren. Die expandierende Gesundheitsbranche und die groß angelegte Datengenerierung im asiatisch-pazifischen Raum positionieren das Land an der Spitze der KI-gesteuerten Innovationen.
Regulatorische Rahmenbedingungen
In den USADie Food and Drug Administration (FDA) reguliert medizinische Geräte, einschließlich Sehtransformatoren, die in der medizinischen Bildgebung und Diagnostik verwendet werden, und stellt die Einhaltung von Standards für Genauigkeit, Sicherheit und Wirksamkeit sicher.
Die der EUDie Datenschutz-Grundverordnung (DSGVO) regelt die Verarbeitung, Übertragung und Verwendung von KI-Modellen personenbezogener Daten und legt den Schwerpunkt auf Einwilligung und Einhaltung.
In IndienDas Gesetz zum Schutz digitaler personenbezogener Daten von 2023 gewährleistet eine rechtmäßige Datenverarbeitung, setzt datentreue Pflichten durch und verhängt Strafen für Verstöße, wobei der Schwerpunkt auf Transparenz, Einwilligung, Sicherheit und dem Schutz der Daten von Kindern liegt.
Wettbewerbslandschaft
Der Markt für Bildtransformatoren verzeichnet ein erhebliches Wachstum, das durch die zunehmende Einführung KI-gestützter Lösungen in der autonomen Technologie gefördert wird.
Unternehmen entwickeln transformatorbasierte Modelle weiter, um die Objekterkennung, die 3D-Kartierung und die Entscheidungsfindung in Echtzeit zu verbessern und so die Sicherheit und Leistung in autonomen Anwendungen zu erhöhen. Diese Innovationsbemühungen verschärfen den Wettbewerb in der gesamten Branche.
Im März 2024 hat Plus seine Visionsmodelle für autonomes Fahren durch die Zusammenarbeit mit NVIDIA weiterentwickelt. Mithilfe der DRIVE Thor-Plattform von NVIDIA, die auf der Blackwell-Architektur der nächsten Generation basiert, möchte Plus seine SuperDrive-Lösung der Stufe 4 verbessern und dabei KI und Transformatoren für sicherere und effizientere autonome Systeme nutzen.
Liste der wichtigsten Unternehmen im Vision Transformers-Markt:
Im Juni 2023Quadric gab bekannt, dass sein Chimera GPNPU-Prozessor-IP Vision Transformer (ViT)-Modelle für maschinelles Lernen unterstützt. Diese Entwicklung ermöglicht eine effiziente ViT-Implementierung für Edge-KI-Systeme, überwindet die Einschränkungen aktueller NPUs und vereinfacht sowohl das Hardwaredesign als auch die Softwareentwicklung für SoC-Geräte.
Im Mai 2023LandingAI hat seine Visual Prompting-Technologie durch die Zusammenarbeit mit der Metropolis for Factories-Plattform von NVIDIA verbessert und so die schnelle Bereitstellung von Vision-Transformer-Modellen für die intelligente Fertigung ermöglicht. Diese Innovation rationalisiert Computer-Vision-Anwendungen und verbessert die Produktionseffizienz, Qualitätskontrolle und Kostensenkung.
Im März 2023BrainChip brachte die zweite Generation seiner Akida-Plattform auf den Markt, die Vision Transformer-Beschleunigung und temporale ereignisbasierte neuronale Netze (TENN) umfasst, um die Edge-KI-Leistung zu verbessern. Diese Innovation ermöglicht die effiziente Verarbeitung komplexer Aufgaben wie Bildklassifizierung und Objekterkennung in Geräten mit geringem Stromverbrauch.
Im März 2023, NVIDIA führte FasterTransformer v6.0 ein und optimierte Transformer-Modelle wie BERT, GPT, ViT und Swin Transformer. Zu den wichtigsten Verbesserungen gehörten Streaming, interaktive Generierung, FP8-Inferenz und Multi-GPU-Unterstützung, was zu einer 4,5-fachen Beschleunigung von MLPerf und einer Verbesserung der KI-Inferenzeffizienz in allen Branchen führte.
Häufig gestellte Fragen
Wie hoch ist die erwartete CAGR für den Markt für Vision-Transformatoren im Prognosezeitraum?
Wie groß war die Branche im Jahr 2023?
Was sind die Hauptfaktoren, die den Markt antreiben?
Wer sind die Hauptakteure auf dem Markt?
Welche ist im prognostizierten Zeitraum die am schnellsten wachsende Region auf dem Markt?
Welches Segment wird im Jahr 2031 voraussichtlich den größten Marktanteil halten?
Autor
Sharmishtha ist eine angehende Research-Analystin mit einem starken Engagement für Spitzenleistungen in ihrem Fachgebiet. Sie geht bei jedem Projekt akribisch vor und geht tief ins Detail, um umfassende und aufschlussreiche Ergebnisse zu gewährleisten. Mit Leidenschaft für kontinuierliches Lernen ist sie bestrebt, ihr Fachwissen zu erweitern und in der dynamischen Welt der Marktforschung an der Spitze zu bleiben. Neben der Arbeit liest Sharmishtha gerne Bücher, verbringt Zeit mit Freunden und Familie und engagiert sich für Aktivitäten, die das persönliche Wachstum fördern.
Mit über einem Jahrzehnt Forschungserfahrung in globalen Märkten bringt Ganapathy scharfsinniges Urteilsvermögen, strategische Klarheit und tiefes Branchenwissen mit. Bekannt für Präzision und unerschütterliches Engagement für Qualität, führt er Teams und Kunden mit Erkenntnissen, die konsequent zu wirkungsvollen Geschäftsergebnissen führen.