Размер рынка Vision Transformers, доля, рост и отраслевой анализ, по предложению (решения, услуги), по применению (классификация изображений, субтитры к изображениям, сегментация изображений, другие), по отраслям конечного использования (здравоохранение и биологические науки, розничная торговля и электронная коммерция, автомобилестроение, правительство и оборона, другие) и региональный анализ, 2024-2031
Страницы: 160 | Базовый год: 2023 | Релиз: март 2025 г. | Автор: Sharmishtha M. | Последнее обновление: февраль 2026 г.
Рынок охватывает разработку и применение моделей видеотрансформаторов для обработки изображений и видео. ViT превосходно фиксируют долгосрочные зависимости и контекстные отношения, что делает их пригодными для классификации изображений, обнаружения объектов и понимания сцены. Их возможности способствуют развитию приложений компьютерного зрения на базе искусственного интеллекта в различных отраслях.
Рынок трансформаторов VisionОбзор
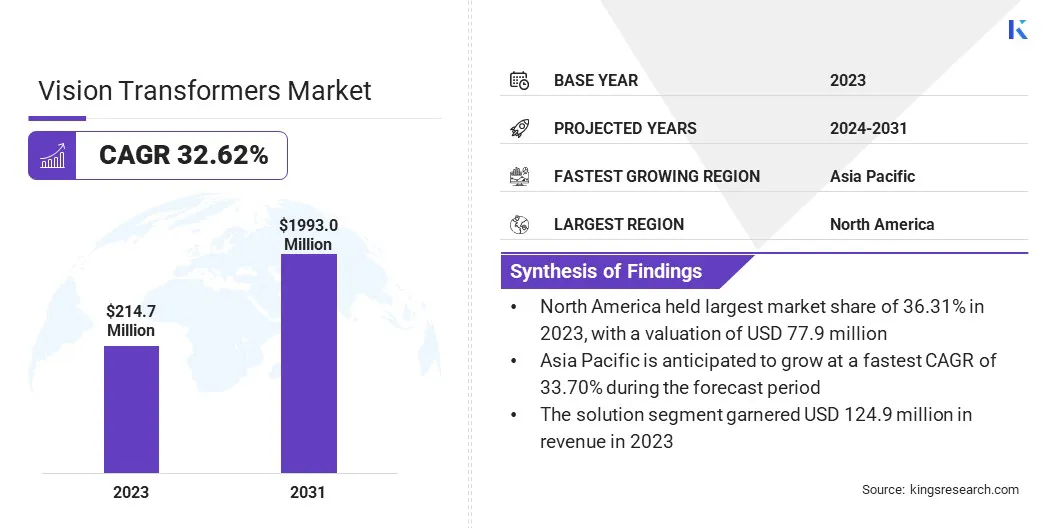
Объем мирового рынка видеотрансформаторов оценивался в 214,7 млн долларов США в 2023 году, который, по оценкам, будет оценен в 276,3 млн долларов США в 2024 году и достигнет 1 993,0 млн долларов США к 2031 году, а среднегодовой темп роста составит 32,62% с 2024 по 2031 год.
Превосходная производительность в сложных задачах, таких как распознавание изображений и обработка естественного языка, стимулирует рост рынка, обеспечивая повышенную точность, масштабируемость и эффективность по сравнению с традиционными методами.
Крупнейшими компаниями, работающими в отрасли преобразователей машинного зрения, являются Google LLC, OpenAI OpCo, LLC, Meta, NVIDIA Corporation, LeewayHertz, Microsoft, Qualcomm Technologies, Inc., viso.ai, Clarifai, Inc., QUADRIC, Datature, Apple Inc., Innova Solutions, V7 Ltd, Ultralytics Inc и другие.
Рынок быстро развивался, став ключевым игроком в области компьютерного зрения. Их сила заключается в фиксации долгосрочных зависимостей, что обеспечивает большую гибкость и масштабируемость, чем традиционные модели.
Благодаря постоянному развитию технологий глубокого обучения и искусственного интеллекта ViT набирают популярность в отраслях здравоохранения, автомобилестроения и безопасности. Поскольку спрос на высокоточные решения для обработки изображений в реальном времени растет, ViT становятся предпочтительным выбором для решений машинного зрения на основе искусственного интеллекта.
В январе 2024 года компания Apple оптимизировала преобразователи машинного зрения (ViT) для Apple Neural Engine (ANE), улучшив скорость обработки и сократив задержки. Такие инновации, как локальные блоки внимания, альтернативные позиционные встраивания и эффективное тензорное секционирование, повысили производительность ViT, что принесло пользу таким приложениям, как классификация изображений и сегментация объектов.
Ключевые моменты:
В 2023 году объем отрасли видеотрансформаторов составил 214,7 млн долларов США.
Прогнозируется, что в период с 2024 по 2031 год рынок будет расти в среднем на 32,62%.
В 2023 году доля Северной Америки составила 36,31% на сумму 77,9 млн долларов США.
В 2023 году выручка сегмента решений составила 124,9 млн долларов США.
Ожидается, что к 2031 году сегмент классификации изображений достигнет 668,9 млн долларов США.
Ожидается, что в сегменте здравоохранения и медико-биологических наук будет наблюдаться самый быстрый среднегодовой темп роста в 34,41% за прогнозируемый период.
Ожидается, что в течение прогнозируемого периода среднегодовой темп роста в Азиатско-Тихоокеанском регионе составит 33,70%.
Драйвер рынка
«Превосходная производительность в сложных задачах»
Способность ViT достигать более высокой точности в сложных задачах компьютерного зрения способствует росту рынка преобразователей машинного зрения. ViT эффективно фиксируют глобальные отношения внутри изображения, в то время как CNN в первую очередь обнаруживают локальные закономерности, такие как края и текстуры.
Эта возможность позволяет ViT более эффективно обрабатывать сложные визуальные данные, что приводит к их широкому внедрению в различных отраслях.
В мае 2024 года Datature запустила первую волну преобразователей изображения для обучения пользовательских моделей и тонкой настройки семантической сегментации: Mask2Former и SegFormer. Эти модели и их варианты устанавливают новые стандарты эффективности семантической сегментации.
Рыночный вызов
«Ограничения памяти»
Ограничения памяти представляют собой серьезную проблему для роста рынка преобразователей машинного зрения, особенно для крупных моделей, обрабатывающих данные высокого разрешения. Этим моделям требуется значительный объем памяти для обработки нескольких токенов и слоев, что ограничивает развертывание на устройствах с ограниченными ресурсами.
Чтобы решить эту проблему, такие методы, как локальное внимание, которое разделяет изображения на более мелкие сегменты, и оптимизированные тензорные макеты, повышают эффективность использования памяти, сокращают время обработки и обеспечивают плавное развертывание, сохраняя при этом точность на различных устройствах.
Рыночный тренд
«Расширение в специализированные приложения»
Расширение ViT на специализированные области, такие какцифровая патологиястановится заметной тенденцией на рынке преобразователей машинного зрения. Эти усовершенствованные модели используются для прецизионной диагностики, повышая точность анализа изображений в таких приложениях, как обнаружение и классификация опухолей.
Обрабатывая крупномасштабные медицинские изображения с высоким разрешением, рынок становится свидетелем перехода к эффективным автоматизированным системам, которые улучшают оказание медицинской помощи и результаты лечения пациентов.
В мае 2024 года Microsoft запустила GigaPath, специализированный преобразователь зрения для цифровой патологии. Разработанный в сотрудничестве с Providence Health System и Вашингтонским университетом, Prov-GigaPath предназначен для анализа целых изображений слайдов, улучшая диагностику рака. Благодаря расширенным возможностям в определении подтипов рака и задачах патомики он призван преобразовать прецизионное здравоохранение.
Снимок отчета о рынке трансформаторов Vision
Сегментация
Подробности
Предлагая
Решение (аппаратное обеспечение, программное обеспечение), услуги (консалтинг, развертывание и интеграция, обучение, поддержка и обслуживание)
По применению
Классификация изображений, субтитры к изображениям, сегментация изображений, обнаружение объектов, другое
По отраслям конечного использования
Здравоохранение и биологические науки, Розничная торговля и электронная коммерция, Автомобильная промышленность, Правительство и оборона, Прочее
По регионам
Северная Америка: США, Канада, Мексика
Европа: Франция, Великобритания, Испания, Германия, Италия, Россия, Остальная Европа.
Азиатско-Тихоокеанский регион: Китай, Япония, Индия, Австралия, АСЕАН, Южная Корея, остальные страны Азиатско-Тихоокеанского региона.
Ближний Восток и Африка: Турция, ОАЭ, Саудовская Аравия, Южная Африка, остальные страны Ближнего Востока и Африки.
Южная Америка: Бразилия, Аргентина, остальная часть Южной Америки.
Сегментация рынка
По предложению (решения и услуги). В 2023 году сегмент решений заработал 124,9 млн долларов США благодаря растущему спросу на более быстрые и эффективные технологии распознавания изображений.
По приложениям (классификация изображений, субтитры к изображениям, сегментация изображений, обнаружение объектов и другие): доля сегмента классификации изображений в 2023 году составила 32,42 %, чему способствовали достижения в области автоматизированных и масштабируемых систем визуального распознавания.
По отраслям конечного использования (здравоохранение и биологические науки, розничная торговля и электронная коммерция, автомобилестроение, правительство и оборона и другие): прогнозируется, что к 2031 году сегмент здравоохранения и биологических наук достигнет 783,7 млн долларов США, что обусловлено растущим внедрением преобразователей зрения в анализе и диагностике медицинских изображений.
Рынок трансформаторов VisionРегиональный анализ
В зависимости от региона рынок подразделяется на Северную Америку, Европу, Азиатско-Тихоокеанский регион, Ближний Восток и Африку и Латинскую Америку.
Доля рынка видеотрансформаторов в Северной Америке в 2023 году составила около 36,31% и оценивалась в 77,9 млн долларов США. Это доминирование подкрепляется сильным присутствием технологических гигантов, исследовательских институтов и развитой инфраструктуры здравоохранения.
США и Канада лидируют во внедрении передовых технологий искусственного интеллекта, в том числе преобразователей зрения, в таких секторах, как цифровая патология, медицинская визуализация и игры. Вигры, преобразователи изображения улучшают качество и стабильность изображения, способствуя значительному повышению производительности и реализма на основе искусственного интеллекта.
В январе 2025 года на выставке CES 2025 NVIDIA представила DLSS 4 с многокадровой генерацией, основанную на модели искусственного интеллекта на основе машинного зрения. Это обновление улучшает качество изображения, уменьшает ореолы и повышает стабильность, обеспечивая до 8-кратного повышения производительности графических процессоров серии GeForce RTX 50.
В течение прогнозируемого периода среднегодовой темп роста отрасли видеотрансформаторов в Азиатско-Тихоокеанском регионе составит 33,70%. AЭтот быстрый рост обусловлен достижениями в области искусственного интеллекта и технологий здравоохранения в таких странах, как Китай, Япония и Индия.
Растущее внимание к точной медицине и цифровому здравоохранению в сочетании с растущими инвестициями в инфраструктуру искусственного интеллекта создает высокий спрос на преобразователи зрения. Растущая индустрия здравоохранения в Азиатско-Тихоокеанском регионе и крупномасштабное генерирование данных ставят его в авангарде инноваций, основанных на искусственном интеллекте.
Нормативно-правовая база
В СШАУправление по санитарному надзору за качеством пищевых продуктов и медикаментов (FDA) регулирует медицинские устройства, включая преобразователи зрения, используемые в медицинской визуализации и диагностике, обеспечивая соответствие стандартам точности, безопасности и эффективности.
ЕСОбщий регламент по защите данных (GDPR) регулирует обработку, передачу и использование моделей ИИ, уделяя особое внимание согласию и соблюдению требований.
В ИндииЗаконопроект о защите цифровых персональных данных 2023 года обеспечивает законную обработку данных, обеспечивает соблюдение фидуциарных обязательств по данным и налагает штрафы за нарушения, уделяя особое внимание прозрачности, согласию, безопасности и защите данных детей.
Конкурентная среда
Рынок преобразователей машинного зрения переживает значительный рост, чему способствует растущее внедрение решений на базе искусственного интеллекта в автономных технологиях.
Компании продвигают модели на основе трансформаторов для улучшения обнаружения объектов, 3D-картографии и принятия решений в реальном времени, повышая безопасность и производительность автономных приложений. Эти инновационные усилия усиливают конкуренцию во всем секторе.
В марте 2024 года Plus усовершенствовала свои концептуальные модели автономного вождения, сотрудничая с NVIDIA. Используя платформу NVIDIA DRIVE Thor, построенную на архитектуре Blackwell следующего поколения, Plus стремится улучшить свое решение SuperDrive уровня 4, используя искусственный интеллект и трансформаторы для создания более безопасных и эффективных автономных систем.
Список ключевых компаний на рынке Vision Transformers:
Последние события (разработка продукта/партнерство/запуск нового продукта)
В июне 2023 годаКомпания Quadric объявила, что ее IP-процессор Chimera GPNPU поддерживает модели машинного обучения Vision Transformer (ViT). Эта разработка обеспечивает эффективную реализацию ViT для периферийных систем искусственного интеллекта, преодолевая ограничения существующих NPU и упрощая как проектирование аппаратного обеспечения, так и разработку программного обеспечения для устройств SoC.
В мае 2023 г.Компания LandingAI усовершенствовала свою технологию визуальных подсказок, сотрудничая с платформой NVIDIA Metropolis for Factory, что позволяет быстро развертывать модели видеотрансформаторов для интеллектуального производства. Это нововведение оптимизирует приложения компьютерного зрения, повышая эффективность производства, контроль качества и снижение затрат.
В марте 2023 г.Компания BrainChip выпустила второе поколение своей платформы Akida, включающей в себя ускорение преобразователя зрения и нейронные сети на основе временных событий (TENN) для повышения производительности периферийного ИИ. Это нововведение обеспечивает эффективную обработку сложных задач, таких как классификация изображений и обнаружение объектов, на устройствах с низким энергопотреблением.
В марте 2023 г.NVIDIA представила FasterTransformer v6.0, оптимизируя такие модели трансформаторов, как BERT, GPT, ViT и Swin Transformer. Ключевые улучшения включали потоковую передачу, интерактивную генерацию, вывод FP8 и поддержку нескольких графических процессоров, что обеспечивает ускорение MLPerf в 4,5 раза и повышение эффективности вывода искусственного интеллекта в различных отраслях.
Часто задаваемые вопросы
Каков ожидаемый среднегодовой темп роста рынка видеотрансформаторов в течение прогнозируемого периода?
Насколько велика была отрасль в 2023 году?
Каковы основные факторы, движущие рынок?
Кто является ключевыми игроками на рынке?
Какой регион на рынке будет наиболее быстрорастущим в прогнозируемый период?
Какой сегмент, как ожидается, будет занимать наибольшую долю рынка в 2031 году?
Автор
Шармиштха — подающий надежды аналитик-исследователь, твердо стремящийся достичь совершенства в своей области. Она тщательно подходит к каждому проекту, глубоко вникая в детали, чтобы обеспечить комплексные и содержательные результаты. Увлеченная непрерывным обучением, она стремится совершенствовать свой опыт и оставаться впереди в динамичном мире рыночных исследований. Помимо работы, Шармиштха любит читать книги, проводить время с друзьями и семьей и заниматься деятельностью, способствующей личностному росту.
Имея более десяти лет опыта руководства исследованиями на глобальных рынках, Ганапати обладает острым суждением, стратегической ясностью и глубокой отраслевой экспертизой. Известный своей точностью и непоколебимой приверженностью качеству, он направляет команды и клиентов с инсайтами, которые постоянно обеспечивают значимые бизнес-результаты.