Speech and Voice Recognition Market Size, Share, Growth & Industry Analysis, By Technology (Speech Recognition, Voice Recognition), By Deployment (Cloud-based, On-premises), By Vertical (Healthcare, IT & Telecommunications, Automotive, BFSI, Government & Legal, Education, Retail, Media & Entertainment, Others) and Regional Analysis, 2025-2032
Páginas: 170 | Ano base: 2024 | Lançamento: July 2025 | Autor: Versha V. | Última atualização: July 2025
O reconhecimento de fala refere -se à capacidade tecnológica de converter a linguagem falada em texto escrito, enquanto o reconhecimento de voz envolve a identificação de indivíduos com base em características vocais distintas. O mercado abrange hardware, software e serviços que interpretam e processam a fala humana.
As principais aplicações incluem assistentes virtuais, transcrição automatizada, sistemas de voz no veículo e autenticação biométrica. Essas tecnologias são utilizadas em vários setores, como assistência médica, finanças, varejo e empresa para execução de comandos e verificação segura do usuário.
Visão geral do mercado de reconhecimento de fala e voz
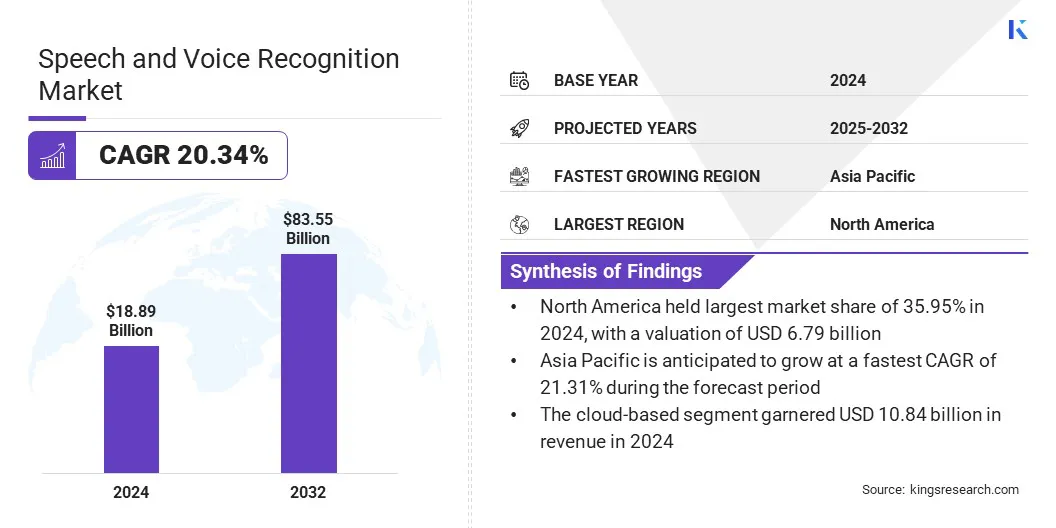
O tamanho do mercado global de reconhecimento de fala e reconhecimento de voz foi avaliado em US $ 18,89 bilhões em 2024 e deve crescer de US $ 22,65 bilhões em 2025 para US $ 83,55 bilhões em 2032, exibindo um CAGR de 20,34% durante o período de previsão.
O mercado está experimentando um crescimento significativo, impulsionado pela crescente integração de tecnologias habilitadas por voz em eletrônicos de consumo, sistemas automotivos e aplicativos corporativos. Maior adoção de assistentes inteligentes, avanços no processamento de linguagem natural e a crescente demanda por interfaces sem contato estão alimentando a expansão do mercado.
Principais destaques
O tamanho da indústria de reconhecimento de fala e voz foi avaliado em US $ 18,89 bilhões em 2024.
O mercado deve crescer a uma CAGR de 20,34% de 2025 a 2032.
A América do Norte detinha uma ação de 35,95% em 2024, avaliada em US $ 6,79 bilhões.
O segmento de reconhecimento de fala recebeu US $ 10,18 bilhões em receita em 2024.
O segmento baseado em nuvem deve atingir US $ 46,23 bilhões até 2032.
O segmento de assistência médica deve gerar uma receita de US $ 14,11 bilhões até 2032.
Prevê -se que a Ásia -Pacífico cresça a um CAGR de 21,31% durante o período de previsão.
Grandes empresas que operam no reconhecimento de fala e vozindústriaApple Inc., Amazon.com, Inc., Alphabet Inc., Microsoft, IBM, Baidu, Iflytek Corporation, Samsung, Meta, SoundHound AI Inc., Sensory Inc., SpeechMatics, Verint Systems Inc., Cisco Systems, Inc. e OpenAi.
As soluções baseadas em voz aprimoram a experiência do usuário, a eficiência operacional e a segurança de dados no setor financeiro, permitindo interações naturais e sem mãos que simplificam o acesso e as transações da conta. Eles automatizam tarefas de rotina, reduzindo a dependência de agentes humanos e reduzem os custos de serviço. Além disso, o reconhecimento de voz fornece autenticação biométrica, garantindo acesso seguro a informações confidenciais e reforçando a confiança no banco digital.
Por exemplo, em abril de 2025, a Omniwire, Inc. fez uma parceria com a Nowutalkai, Inc. para lançar o primeiro banqueiro pessoal da AI Voice usando a tecnologia 'Voice to Action' da Nowutalkai. O assistente de conversação multilíngue é oferecido como uma solução de rótulo branco para bancos, fintechs e cooperativas de crédito, permitindo o banco de voz segura e de primeira vez através da plataforma bancária baseada em nuvem da Omniwire como serviço.
Esse desenvolvimento demonstra a integração de tecnologias de voz avançadas nas plataformas bancárias principais atendem à demanda por serviços financeiros seguros, eficientes e fáceis de usar, impulsionando assim o crescimento do mercado.
Piloto de mercado
Adoção crescente de assistentes virtuais movidos a IA
O progresso do mercado global de reconhecimento de fala e voz é alimentado principalmente pela crescente integração de assistentes virtuais movidos a IA em eletrônicos de consumo e dispositivos inteligentes.
À medida que empresas e famílias adotamalto -falantes inteligentes, smartphones e sistemas de infotainment no carro, a demanda por interfaces de voz precisas e responsivas aumentam. Esses sistemas habilitados para a AI melhoram a experiência do usuário, permitindo operações sem-livre, recuperação eficiente de informações e execução de tarefas em tempo real, promovendo a conveniência e a acessibilidade.
A integração do processamento avançado de linguagem natural (PNL) e algoritmos de aprendizado de máquina permite que esses sistemas entendam a fala, sotaques e comandos de usuário contextuais com alta precisão. Além disso, as empresas estão se concentrando na criação de interfaces de voz mais personalizadas e com conhecimento de contexto que se alinham às expectativas em evolução do usuário. Essa crescente dependência de tecnologias baseadas em voz contribui significativamente para a expansão do mercado.
Em fevereiro de 2025, a Amazon lançou o Alexa+, um assistente generativo de IA, projetado para interações naturais e inteligentes de voz. Integrado ao avançado LLMS, o Alexa+ aprimora a automação de tarefas, o controle da casa inteligente e a assistência personalizada entre os dispositivos. Essa atualização pretende oferecer experiências de conversação em tempo real e em tempo real.
Desafio de mercado
Sotaque e limitações contextuais no reconhecimento de fala
Um grande desafio que impede o desenvolvimento do mercado de reconhecimento de fala e voz é a interpretação precisa de diversos sotaques, dialetos e uso de idiomas dependentes do contexto. Isso geralmente leva a uma precisão reduzida, particularmente em configurações ou ambientes multilíngues com altos níveis de ruído ambiente, afetando a experiência do usuário e a confiabilidade do sistema.
Para enfrentar esse desafio, as empresas estão desenvolvendo modelos avançados de processamento de linguagem natural (PNL) que incorporam técnicas de aprendizado profundo e são treinadas em conjuntos de dados extensos e linguisticamente diversos. Esses modelos são projetados para melhorar a capacidade do sistema de reconhecer variações de fala diferenciadas e entender a intenção do usuário com mais eficiência.
Além disso, as melhorias na conscientização contextual estão permitindo que os sistemas interpretem melhor as pistas de conversação, suportando acessibilidade mais ampla e desempenho do mundo real.
Em março de 2025, a OpenAI introduziu um novo conjunto de modelos de áudio de próxima geração por meio de sua API, com recursos de fala para texto e texto e expressão de texto. Projetado para alta precisão e confiabilidade em condições acústicas desafiadoras, o lançamento suporta o desenvolvimento de agentes de voz personalizáveis e inteligentes em diversas aplicações.
Tendência de mercado
Integração do reconhecimento de fala no setor de saúde
O mercado global de reconhecimento de fala e voz é influenciado pela integração das tecnologias de Voice AI nos sistemas de saúde. Essa tendência está aumentando a adoção de ferramentas avançadas habilitadas por voz que otimizam os fluxos de trabalho clínicos, reduzem os encargos administrativos e aprimoram o envolvimento do paciente.
Integrar os recursos de reconhecimento de fala emRegistro de saúde eletrônico (EHR)As plataformas e os processos de documentação clínica melhoram a precisão, agilizam a entrada de dados e aumentam a produtividade do clínico.
A capacidade desses sistemas de interpretar a linguagem natural, apoiar a comunicação multilíngue e automatizar tarefas repetitivas aprimora significativamente a eficiência operacional e a qualidade dos cuidados. Além disso, a crescente demanda por soluções ambientais e de mãos livres em ambientes de saúde está promovendo o investimento contínuo em aplicativos de saúde habilitados para voz, posicionando a fala e o reconhecimento de voz como um componente crítico na transformação digital dos serviços globais de saúde.
Em março de 2025, a Microsoft Corp. introduziu a Dragon Copilot, um assistente de voz movido a IA para fluxos de trabalho clínicos. A solução integra o Dragon Medical One e o DAX copilot para otimizar a documentação, automatizar tarefas administrativas e aprimorar a eficiência do clínico. Construído na Microsoft Cloud for Healthcare, o Dragon Copilot combina audição ambiente, processamento de linguagem natural e IA generativa para melhorar o bem-estar do fornecedor e os resultados dos pacientes.
Relatório de mercado de fala e reconhecimento de voz instantâneo
Segmentação
Detalhes
Por tecnologia
Reconhecimento de fala, reconhecimento de voz
Por implantação
Baseado em nuvem, local
Por vertical
Saúde, TI e telecomunicações, automotivo, BFSI, governo e jurídico, educação, varejo, mídia e entretenimento, outros
Por região
América do Norte: EUA, Canadá, México
Europa: França, Reino Unido, Espanha, Alemanha, Itália, Rússia, Resto da Europa
Ásia-Pacífico: China, Japão, Índia, Austrália, ASEAN, Coréia do Sul, Resto da Ásia-Pacífico
Oriente Médio e África: Turquia, U.A.E., Arábia Saudita, África do Sul, Resto do Oriente Médio e África
Ámérica do Sul: Brasil, Argentina, Resto da América do Sul
Segmentação de mercado
Por tecnologia (reconhecimento de fala e reconhecimento de voz): o segmento de reconhecimento de fala ganhou US $ 10,18 bilhões em 2024 devido à sua ampla adoção em assistentes virtuais, serviços de transcrição e automação de atendimento ao cliente entre os setores.
Por implantação (baseada em nuvem e local): o segmento baseado em nuvem detinha uma parte de 57,37%em 2024, alimentada por sua escalabilidade, facilidade de integração e custos de infraestrutura mais baixos.
Por vertical (assistência médica, TI e telecomunicações, automotivo, BFSI, governo e jurídico, educação, varejo, mídia e entretenimento e outros): o segmento de saúde deve atingir US $ 14,11 bilhões em 2032, devido ao aumento das ferramentas de documentação clínica e de engajamento clínico habilitadas por voz.
Análise regional do mercado de reconhecimento de fala e voz
Com base na região, o mercado foi classificado na América do Norte, Europa, Ásia -Pacífico, Oriente Médio e África e América do Sul.
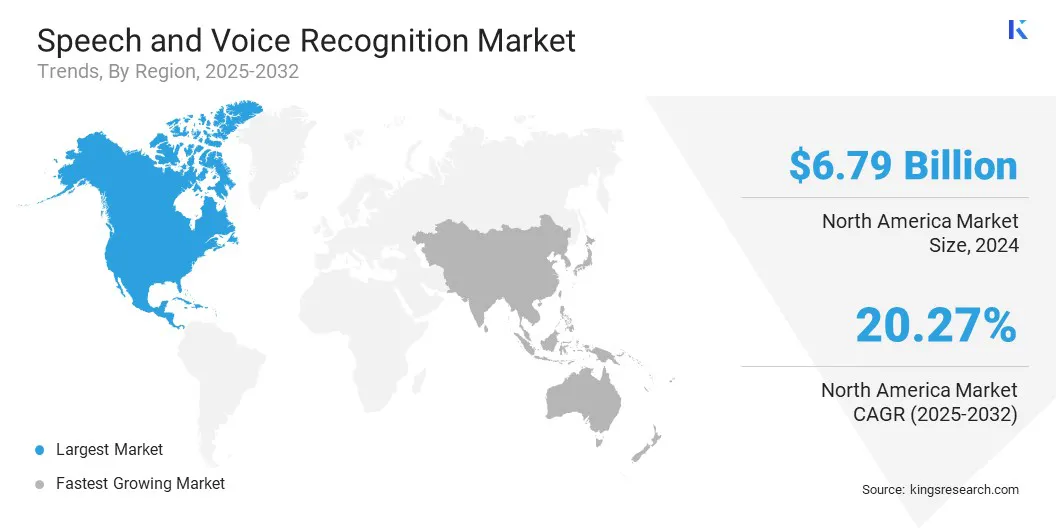
O mercado de reconhecimento de fala e voz da América do Norte representou uma participação substancial de 35,95% em 2024, avaliada em US $ 6,79 bilhões. Esse domínio é reforçado por um forte investimento em tecnologias de inteligência artificial e processamento de linguagem natural, que avançaram significativamente as capacidades dos sistemas habilitados por voz.
Essas inovações estão cada vez mais integradas a eletrônicos de consumo, software corporativo e serviços digitais, promovendo experiências de usuário sem mãos e sem mãos. A disponibilidade de alta infraestrutura digital, talento qualificado e adoção de tecnologia precoce acelera ainda mais essa tendência.
Com a voz emergindo como uma interface primária para a interação de dispositivos e aplicativos, as empresas e os consumidores da América do Norte estão adotando ferramentas de reconhecimento de fala e voz, solidificando a posição de liderança da região.
Em janeiro de 2025, a Elevenlabs levantou 180 milhões de dólares em financiamento da Série C para avançar sua tecnologia de áudio de IA, expandir sua pesquisa e desenvolver novos produtos que façam voz e soam centrais para as interações digitais.
O discurso da Ásia-Pacífico e o reconhecimento de vozindústriaDeve -se registrar o CAGR mais rápido de 21,31% durante o período de previsão. Esse crescimento é promovido principalmente pela expansão da penetração de smartphones e pela integração de assistentes de voz em dispositivos móveis.
Com uma população grande e crescente de usuários de primeira linha, especialmente em países como China, Índia e Nações do Sudeste Asiático, há uma forte demanda por interação intuitiva e localizada da voz. Fabricantes e provedores de serviços estão integrando recursos de reconhecimento de voz para aprimorar a acessibilidade, a conveniência do usuário e a personalização em idiomas e dialetos nativos.
Essa tendência da interface de voz centrada no celular está transformando o envolvimento digital em setores como comércio eletrônico, bancos, assistência médica e educação. A ascensão de smartphones acessíveis com recursos de IA incorporados alimenta ainda mais esse crescimento.
Em dezembro de 2023, o Instituto de Pesquisa Infocomm de Star, IMDA e AI Singapore, fizeram uma parceria para lançar o primeiro modelo regional de grandes idiomas do sudeste da Ásia no programa nacional Multimodal LLM de Cingapura. A iniciativa visa desenvolver modelos culturalmente contextuais de texto de fala, adaptados às línguas do sudeste asiático, aprimorando os recursos de interação de voz local.
Estruturas regulatórias
Nos EUA, a Comissão Federal de Comércio (FTC) e a Federal Communications Commission (FCC) regulam as tecnologias de voz sob leis de proteção e comunicação do consumidor, com foco em privacidade, vigilância e práticas de negócios justas.
Na Europa, o Regulamento Geral de Proteção de Dados (GDPR) rege a coleta, processamento e armazenamento de dados de voz, exigindo que as empresas garantam transparência, consentimento do usuário e minimização de dados ao implantar tecnologias de reconhecimento de voz.
Na China, a administração do ciberespaço da China (CAC) aplica a Lei de Proteção de Informações Pessoais (PIPL), que inclui requisitos estritos para dados biométricos, como voz, garantindo armazenamento de dados locais e consentimento do usuário.
No Japão, a Comissão de Proteção de Informações Pessoais (PPC) supervisiona a Lei sobre a Proteção de Informações Pessoais (APPI), que regula o uso de dados de voz, particularmente em aplicativos que envolvem autenticação biométrica ou perfil de voz.
Cenário competitivo
O reconhecimento global de fala e vozindústriaé caracterizado por uma rápida inovação tecnológica, apoiada pela crescente integração de interfaces de voz em dispositivos e soluções corporativas do dia a dia.
As empresas estão colaborando ativamente com instituições de pesquisa de IA e provedores de serviços em nuvem para co-desenvolver aplicativos avançados habilitados por voz, com o objetivo de fornecer processamento de fala mais rápido, mais preciso e consciente do contexto. Essas colaborações estão permitindo que as empresas aprimorem os recursos de análise de voz e melhorem a capacidade de resposta do sistema em diversos ambientes, como call centers, automóveis e dispositivos inteligentes.
As empresas estão lançando ainda mais plataformas de reconhecimento de voz criadas para fins específicos que podem ser facilmente incorporados aos fluxos de trabalho corporativos, oferecendo escalabilidade e adaptabilidade multilíngue. Essa mudança contínua em direção à integração, personalização e otimização de desempenho está intensificando a concorrência, com os jogadores se esforçando para se diferenciar através de modelos proprietários e soluções de voz específicas da região adaptadas às necessidades do usuário.
Em março de 2025, a Kyndryl colaborou com a Microsoft para lançar o Dragon Copilot, um assistente de assistência médica movido a IA que alavancava IA generativa para audição ambiente e reconhecimento de voz. A parceria visa automatizar a documentação clínica, aprimorar a eficiência do clínico e melhorar o atendimento ao paciente, integrando o ditado de voz e as capacidades de linguagem natural nos fluxos de trabalho da saúde.
Em setembro de 2024, a Deepgram lançou sua API de agente de voz, uma solução unificada de voz a voz, permitindo conversas em tempo real e com som natural entre humanos e máquinas. A API integra o reconhecimento avançado de fala e a síntese de voz para ajudar empresas e desenvolvedores a criar vice -vice -acotos e agentes de IA inteligentes para aplicativos, como suporte ao cliente e processamento de pedidos.
Principais empresas no mercado de discursos e reconhecimento de voz:
Desenvolvimentos recentes (lançamentos/colaborações de produtos)
Em abril de 2025, Aiola introduziu o Jargônico, um modelo ASR de fundação projetado para transcrição em tempo real, específica de domínio, usando o Spotting de palavras-chave e o aprendizado de tiro zero. O Jargonic oferece desempenho superior em ambientes industriais barulhentos, lida com o reconhecimento multilíngue de fala e supera os concorrentes na taxa de erro de palavras e no recall de termos de jargão sem exigir a reciclagem para novos vocabulários do setor.
Em abril de 2025A Kia expandiu seu sistema generativo de reconhecimento de voz, assistente de IA, para o mercado europeu por meio de atualizações ao ar. Inicialmente introduzido na Coréia e nos Estados Unidos, o sistema permite a interação natural e o controle aprimorado de veículos e estará disponível nos modelos EV3 e outros modelos equipados com CCNC.
Em abril de 2025, O Intelepeer lançou recursos avançados de Voice AI com reconhecimento automático de fala (ASR) e streaming de texto para fala (TTS). Desenvolvido internamente, a tecnologia permite conversas em tempo real, aprimora a experiência do cliente por meio de interações naturais e baixa latência e fortalece a plataforma de IA de conversação de ponta a ponta da empresa com análises, detecção de idiomas e configurações de automação personalizáveis.
Em junho de 2024, Philips Discurso da Speech Processing Solutions colaborou com a Sembly AI para lançar três novos gravadores de áudio integrados à tecnologia de IA. Os dispositivos oferecem transcrições automáticas, resumos, listas de ação e insights, enquanto o Sembly AI adiciona separação de alto-falantes, notas de reunião e recursos que aumentam a produtividade.
Perguntas frequentes
Qual é o CAGR esperado para o mercado de reconhecimento de fala e voz durante o período de previsão?
Qual o tamanho da indústria em 2024?
Quais são os principais fatores que impulsionam o mercado?
Quem são os principais players do mercado?
Qual região deve ser a que mais cresce no mercado durante o período de previsão?
Qual segmento previsto para manter a maior parte do mercado em 2032?
Autor
Versha traz mais de 15 anos de experiência no gerenciamento de projetos de consultoria em vários setores, incluindo alimentos e bebidas, bens de consumo, TIC, aeroespacial e muito mais. Sua experiência em vários domínios e adaptabilidade fazem dela uma profissional versátil e confiável. Com habilidades analíticas aguçadas e uma mentalidade curiosa, Versha se destaca na transformação de dados complexos em insights acionáveis. Ela tem um histórico comprovado de desvendar a dinâmica do mercado, identificar tendências e fornecer soluções personalizadas para atender às necessidades dos clientes. Como líder qualificado, Versha orientou com sucesso equipes de pesquisa e dirigiu projetos com precisão, garantindo resultados de alta qualidade. Sua abordagem colaborativa e visão estratégica permitem que ela transforme desafios em oportunidades e entregue resultados impactantes de forma consistente. Seja analisando mercados, envolvendo partes interessadas ou elaborando estratégias, Versha baseia-se em sua profunda experiência e conhecimento do setor para impulsionar a inovação e entregar valor mensurável.
Com mais de uma década de liderança em pesquisa em mercados globais, Ganapathy traz julgamento aguçado, clareza estratégica e profunda expertise na indústria. Conhecido por sua precisão e compromisso inabalável com a qualidade, ele orienta equipes e clientes com insights que impulsionam consistentemente resultados empresariais impactantes.


 Mercado de reconhecimento de fala e voz
Mercado de reconhecimento de fala e voz