Taille du marché de la génération de données synthétiques, part, croissance et analyse de l’industrie, par données (données tabulaires, données textuelles, données d’image et vidéo, autres), par application (gestion des données de test, formation et développement de l’IA, partage de données d’entreprise, analyse et visualisation de données), par utilisateur final (services financiers, vente au détail, soins de santé, autres) et analyse régionale, 2026-2033
Pages: 180 | Année de base: 2025 | Version: février 2026 | Auteur: Ashim L. | Dernière mise à jour: mars 2026
Les données synthétiques sont des données artificielles conçues pour imiter les données du monde réel. Il est généré artificiellement mais conserve les propriétés statistiques des données originales à partir desquelles il a été généré. La génération de données synthétiques peut se produire sous forme de tableau, multimédia ou texte. Les données textuelles synthétiques peuvent être utiles pour le traitement du langage naturel (NLP). De même, les données tabulaires ont des applications dans la création de tables de bases de données relationnelles.
Le multimédia synthétique comprend des images, des vidéos et d'autres données non structurées, qui peuvent être cruciales pour les tâches de vision par ordinateur telles que la reconnaissance et la classification d'images, entre autres. Les besoins en données augmentent dans des secteurs tels que la finance, la santé et la vente au détail. Les données synthétiques aident ces organisations en accélérant l’innovation en matière d’IA et en permettant des décisions plus intelligentes.
Marché de la génération de données synthétiquesAperçu
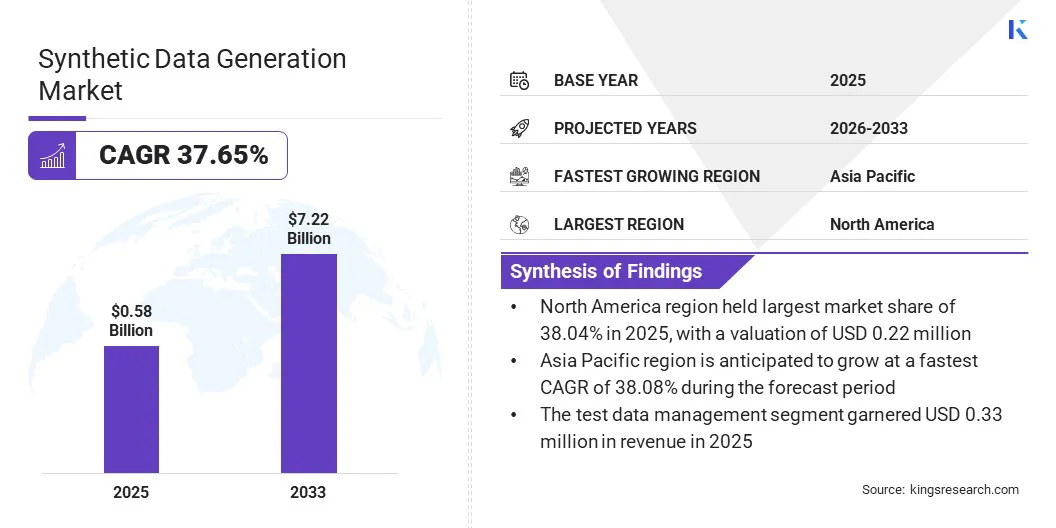
La taille du marché mondial de la génération de données synthétiques était évaluée à 0,58 milliard de dollars en 2025 et devrait passer de 0,77 milliard de dollars en 2026 à 7,22 milliards de dollars d’ici 2033, avec un TCAC de 37,65 % au cours de la période de prévision. Cette croissance est attribuée à son application pour tester les systèmes, former des modèles d’IA et simuler des scénarios, ce qui est généralement difficile à capturer dans des données réelles.
Par exemple, dans le secteur de la santé, les dossiers médicaux synthétiques peuvent indiquer des affections telles que le diabète, une maladie ou le cancer, ce qui peut aider à développer et à tester des outils de diagnostic ainsi que des modèles de santé prédictifs.
Les principales entreprises opérant sur le marché mondial de la génération de données synthétiques sont MOSTLY AI, Datagen, TonicAI, Inc., GenRocket, Inc, NVIDIA (Gretel Labs), K2view Ltd, CapGemini (Sogeti), CVEDIA Inc, Microsoft Corporation et MDClone, entre autres.
La demande de données synthétiques devrait croître avec leur utilisation croissante dans plusieurs secteurs, notamment le secteur automobile pour les tests devéhicules autonomes, les soins de santé pour l'analyse d'imagerie médicale et le diagnostic des patients. Dans le secteur de la vente au détail, il est largement utilisé pour la gestion des investissements et l'analyse du comportement des clients.
Cela peut être bénéfique en finance pour la détection des fraudes et l’évaluation des risques. Le principal avantage des données synthétiques réside dans la rentabilité, l’évolutivité et la diversité. Ceux-ci sont largement utilisés dans la formation de modèles d’apprentissage automatique. Il offre un meilleur contrôle sur la qualité des données et préserve également la confidentialité en éliminant l'utilisation de données réelles et sensibles.
La tendance récente indique l’intégration de l’apprentissage fédéré et de la confidentialité différentielle pour améliorer l’apprentissage automatique préservant la confidentialité. En outre, la demande d’ensembles de données de formation diversifiés et de haute qualité augmentera avec l’expansion de l’IA dans de nouveaux domaines, ce qui rendra les données synthétiques très cruciales.
Points saillants :
La taille du marché mondial de la génération de données synthétiques a été enregistrée à 0,58 milliard de dollars en 2025.
Le marché devrait croître à un TCAC de 37,65 % de 2026 à 2033.
L'Amérique du Nord détenait une part de 38,04 % en 2025, évaluée à 0,22 milliard de dollars.
Le segment des données tabulaires a généré 0,20 milliard de dollars de revenus en 2025.
Le segment de la gestion des données de test devrait atteindre 4,05 milliards de dollars d'ici 2033.
Le segment des soins de santé devrait connaître le TCAC le plus rapide de 38,28 % au cours de la période de prévision.
L’Asie-Pacifique devrait connaître une croissance à un TCAC de 38,08 % au cours de la période de projection.
Dans quelle mesure les données synthétiques sont-elles fiables pour la formation en IA ?
Les données synthétiques, lorsqu'elles sont générées à l'aide de techniques robustes, peuvent correspondre ou, dans certains cas, surpasser les données réelles en termes de performances du modèle, en particulier dans les scénarios d'événements rares.
Bien qu'il ne puisse pas remplacer les données réelles, il est très efficace pour prendre en charge les données réelles, en particulier lorsque l'équipe traite des données limitées, des ensembles de données déséquilibrés ou des contraintes de confidentialité. En conséquence, il peut fonctionner comme un complément puissant aux données réelles plutôt que comme un remplacement complet.
En octobre 2024, MOSTLY AI a dévoilé sa nouvelle fonctionnalité de texte synthétique pour la formation des modèles d’IA, et prend également en charge la confidentialité des données propriétaires. Il aide l'organisation à utiliser un large éventail de données textuelles telles que les e-mails, les conversations de chatbot, les transcriptions du support client, etc., pour former et affiner legrands modèles de langage (LLM), et il n’y a aucun risque de violation de la vie privée.
Pourquoi la formation des systèmes d’IA nécessite-t-elle d’être conscient que les données synthétiques peuvent créer de faux résultats ?
Les données synthétiques peuvent manquer de la complexité et des nuances des données du monde réel, ce qui peut entraîner de mauvaises performances des modèles d'IA dans des scénarios du monde réel. De plus, il est possible que les modèles d’IA entièrement formés sur des données synthétiques ne puissent pas se généraliser efficacement aux situations du monde réel en raison des disparités entre les données synthétiques et réelles. Cela pourrait également soulever des problèmes éthiques dans certaines applications, telles que le diagnostic médical.
Comment la génération de données synthétiques offre-t-elle des avantages commerciaux en termes de coût et d’évolutivité ?
La collecte de données réelles est coûteuse et lente en raison de l'association du déploiement des capteurs, de l'étiquetage et de la sécurité. Mais les données synthétiques destinées à l’apprentissage automatique en ligne peuvent être facilement générées à moindre coût et plus rapidement. Les données synthétiques offrent des sources de données contrôlées et évolutives pour un développement robuste de l'IA. Par exemple, des organisations telles que Nvidia et Databricks proposent des outils tels que Unity Catalog et Omniverse Replicator pour automatiser les pipelines de données synthétiques. On estime qu’environ 50 à 60 % des données utilisées pour la formation des plateformes d’IA sont synthétiques. Sa demande augmente car elle aide les organisations à simuler de nouveaux produits, à accélérer le développement de modèles d'IA et à protéger les informations sensibles.
En octobre 2025, GenRocket a annoncé le lancement de son accélérateur de données non structurées (UDA), qui a conduit l'organisation de génération de données synthétiques axée sur la conception à étendre sa plate-forme au-delà des données structurées vers des images, des documents et des formats basés sur des fichiers. Il a aidé l'organisation à générer toute forme de données de manière sûre, précise et à grande échelle, à la demande.
Aperçu du rapport sur le marché de la génération de données synthétiques
Segmentation
Détails
Par données
Données tabulaires, données texte, données image et vidéo, autres
Par candidature
Gestion des données de test, formation et développement de l'IA, partage de données d'entreprise, analyse et visualisation des données
Par utilisateur final
Services financiers, vente au détail, soins de santé et autres
Par région
Amérique du Nord: États-Unis, Canada, Mexique
Europe: France, Royaume-Uni, Espagne, Allemagne, Italie, Russie, Reste de l'Europe
Asie-Pacifique: Chine, Japon, Inde, Australie, ASEAN, Corée du Sud, Reste de l'Asie-Pacifique
Moyen-Orient et Afrique: Turquie, Émirats arabes unis, Arabie Saoudite, Afrique du Sud, reste du Moyen-Orient et Afrique
Amérique du Sud: Brésil, Argentine, Reste de l'Amérique du Sud
Segmentation du marché
Par données (données tabulaires, données textuelles, données d'images et vidéo et autres) : le segment des données tabulaires a généré 0,20 milliard de dollars de revenus en 2025, principalement en raison de son adoption croissante dans les secteurs du commerce électronique et de la santé. Il est largement utilisé pour entraîner efficacement certains modèles d’apprentissage automatique.
Par application (gestion des données de test, formation et développement de l'IA, partage de données d'entreprise et analyse et visualisation des données) : le segment de la formation et du développement de l'IA est sur le point d'enregistrer un TCAC stupéfiant de 38,08 % au cours de la période de prévision, propulsé par ses larges exigences en matière de formation de modèles d'apprentissage automatique. Il constitue une solution potentielle pour les scénarios dans lesquels des données sont nécessaires, mais où il existe une pénurie de données réelles de haute qualité pour la formation des modèles d'IA.
Par utilisateur final (services financiers, vente au détail, soins de santé et autres) : le segment des services financiers devrait détenir une part de 32,13 % d'ici 2032, alimenté par les avantages des données synthétiques tels que le partage sécurisé de données et le développement de modèles pour l'évaluation des risques, la détection des fraudes et l'analyse sans exposer les informations réelles des clients. La génération de données synthétiques peut être possible pour des événements rares tels que des krachs boursiers ou des formes de fraude complexes, ce qui contribue à améliorer les performances du modèle et à accélérer le développement de l'IA.
Quel est le scénario de marché en Amérique du Nord et dans la région Asie-Pacifique ?
En fonction de la région, le marché mondial de la génération de données synthétiques a été classé en Amérique du Nord, en Europe, en Asie-Pacifique, au Moyen-Orient et en Afrique et en Amérique du Sud.
Le marché nord-américain de la génération de données synthétiques représentait une part de 38,04 % en 2025, évaluée à 0,22 milliard de dollars. Cette domination est attribuée à une combinaison d’infrastructures technologiques avancées et d’investissements accrus en R&D dans la région. Aux États-Unis, en particulier, les entreprises adoptent les dernières technologies pour réduire les risques et l'inefficacité.
De plus, les consommateurs préfèrent soutenir les marques qui se concentrent sur les innovations incrémentales. Dans le commerce de détail, la génération de données synthétiques aide à analyser les préférences des clients telles que les habitudes d'achat et la demande saisonnière, tout en protégeant la confidentialité. La région a des obligations croissantes en matière de confidentialité des données et un écosystème d’IA solide, ce qui crée un environnement favorable à la croissance du marché.
En juin 2021, CVEDIA a annoncé une solution pour combler le déficit d'adoption des domaines en utilisant le pipeline de données synthétiques propriétaire. Ils peuvent contribuer au développement de l’IA en permettant aux algorithmes formés sur des données synthétiques de fonctionner avec ceux formés sur des données réelles. CVEDIA revendique une amélioration de la précision de 170 % et un gain de rappel de 160 % par rapport aux modèles de référence.
Le marché de la génération de données synthétiques en Asie-Pacifique devrait croître à un TCAC de 38,08 % au cours de la période de prévision. Cette croissance notable est soutenue par l’utilisation croissante de données synthétiques dans plusieurs domaines de la région, tels que la santé, l’industrie manufacturière, etc.
Par exemple, dans le domaine de la santé, les données synthétiques sont générées pour créer des dossiers de patients réalistes, qui facilitent la recherche tout en offrant l'anonymisation et l'agrégation. Il aide les chercheurs en médecine à développer et tester des algorithmes de diagnostic et de traitement tout en respectant les réglementations strictes en matière de protection des données.
Dans le secteur manufacturier, les constructeurs automobiles utilisent des données synthétiques pour simuler un certain nombre de scénarios de conduite pour les voitures autonomes. Il aide à former des modèles d'apprentissage automatique pour reconnaître et répondre à plusieurs conditions sans nécessiter une collecte approfondie de données réelles. Des entreprises telles que Waymo et Tesla révolutionnent l’utilisation de données synthétiques pour entraîner leurs voitures autonomes.
Cadres réglementaires
Le Règlement général sur la protection des données (RGPD) contrôle le traitement des données personnelles dans l'UE et définit ce qui est considéré comme des données anonymisées ou synthétiques.
La loi britannique Data (Use and Access) Act 2025 prend en charge les dispositions relatives au traitement et à l'accès aux données personnelles et professionnelles. Il met à jour le cadre existant du RGPD britannique et de la loi sur la protection des données.
Aux États-Unis (Californie), le California Consumer Privacy Act (CCPA) et son amendement, le California Privacy Rights Act (CPRA) régissent la collecte et l'utilisation des données personnelles.
Paysage concurrentiel
Les principaux acteurs du marché de la génération de données synthétiques se concentrent largement sur l’innovation technologique continue. Il existe de nombreux petits et moyens acteurs qui ciblent des types et des secteurs de données particuliers. Les vendeurs spécialisés ne détiennent pas de part de marché dominante et opèrent sur des segments de niche.
Les grandes plates-formes de cloud computing et d'IA, telles que Microsoft et NVIDIA, occupent entre autres une part clé du marché, car les capacités de données synthétiques sont présentes dans des services d'IA et de ML plus larges. L'accent est également mis sur les partenariats et les acquisitions pour obtenir des avantages stratégiques.
En mars 2025, Nvidia a acquis Gretel, une startup de données synthétiques, pour plus de 320 millions de dollars, ce qui vient enrichir sa suite de services d'IA générative destinés aux développeurs. Gretel entretient des partenariats avec les principaux fournisseurs de cloud tels que Google Cloud, Amazon Web Services et Microsoft.
Entreprises clés du marché de la génération de données synthétiques :
En avril 2023, MDClone a annoncé que sa plateforme ADAMS permettait davantage de partenariats entre les organisations de prestataires de soins de santé et les entreprises des sciences de la vie pour accélérer la recherche et le développement thérapeutiques.
Questions fréquemment posées
Quels sont les principaux moteurs du marché de la génération de données synthétiques ?
Quelles régions sont au cœur de la croissance de la génération de données synthétiques ?
À quels défis l’industrie de la génération de données synthétiques est-elle confrontée aujourd’hui ?
Quelles tendances façonnent l’avenir de la génération de données synthétiques ?
Quels sont les principaux acteurs de ce secteur ?
Quelles opportunités existent pour les investisseurs ?
Comment ce rapport m'aide-t-il à concentrer notre stratégie de croissance sur la région géographique la plus prometteuse ?
Comment ce rapport m'aide-t-il à comprendre quelle catégorie de DONNÉES a le plus grand impact économique ?
Auteur
Ashim supervise les missions d'intelligence de marché syndiquées et personnalisées, de la conception à la livraison. Il se spécialise dans l’intelligence de marché, la modélisation de la croissance, la stratégie concurrentielle et l’aide à la décision des dirigeants. Son approche de leadership met l’accent sur la clarté de la pensée et un impact commercial mesurable.
Avec plus d'une décennie de leadership en recherche sur les marchés mondiaux, Ganapathy apporte un jugement aigu, une clarté stratégique et une expertise approfondie du secteur. Connu pour sa précision et son engagement inébranlable envers la qualité, il guide les équipes et les clients avec des insights qui génèrent constamment des résultats commerciaux impactants.