El tamaño del mercado del mercado de reconocimiento de voz y voz, el análisis, el crecimiento y el análisis de la industria, por tecnología (reconocimiento de voz, reconocimiento de voz), por despliegue (basado en la nube, en las instalaciones), por vertical (atención médica, TI y telecomunicaciones, automotriz, BFSI, gobierno y legal, educación, minorista, medios y entretenimiento, otros) y análisis regionales, análisis, análisis, análisis regionales, 2025-2032
Páginas: 170 | Año base: 2024 | Lanzamiento: July 2025 | Autor: Versha V. | Última actualización: July 2025
El reconocimiento de voz se refiere a la capacidad tecnológica para convertir el lenguaje hablado en texto escrito, mientras que el reconocimiento de voz implica identificar a las personas basadas en características vocales distintas. El mercado abarca hardware, software y servicios que interpretan y procesan el discurso humano.
Las aplicaciones clave incluyen asistentes virtuales, transcripción automatizada, sistemas de voz en el vehículo y autenticación biométrica. Estas tecnologías se utilizan en varias industrias, como la atención médica, las finanzas, el comercio minorista y la empresa para la ejecución de comandos y la verificación segura del usuario.
Descripción general del mercado de reconocimiento de voz y voz
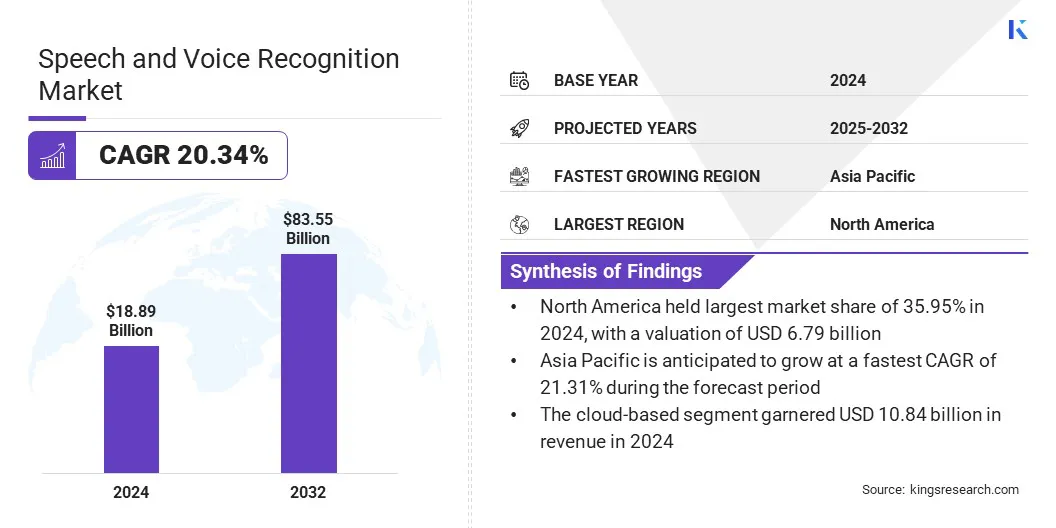
El tamaño del mercado global de reconocimiento de voz y voz se valoró en USD 18.89 mil millones en 2024 y se prevé que crecerá de USD 22.65 mil millones en 2025 a USD 83.55 mil millones por 2032, exhibiendo una tasa compuesta anual de 20.34% durante el período de pronóstico.
El mercado está experimentando un crecimiento significativo, impulsado por la creciente integración de tecnologías habilitadas para la voz en la electrónica de consumo, los sistemas automotrices y las aplicaciones empresariales. Una mayor adopción de asistentes inteligentes, avances en el procesamiento del lenguaje natural y la creciente demanda de interfaces sin contacto están alimentando la expansión del mercado.
Destacados clave
El tamaño de la industria de reconocimiento de voz y voz se valoró en USD 18.89 mil millones en 2024.
Se proyecta que el mercado crecerá a una tasa compuesta anual de 20.34% de 2025 a 2032.
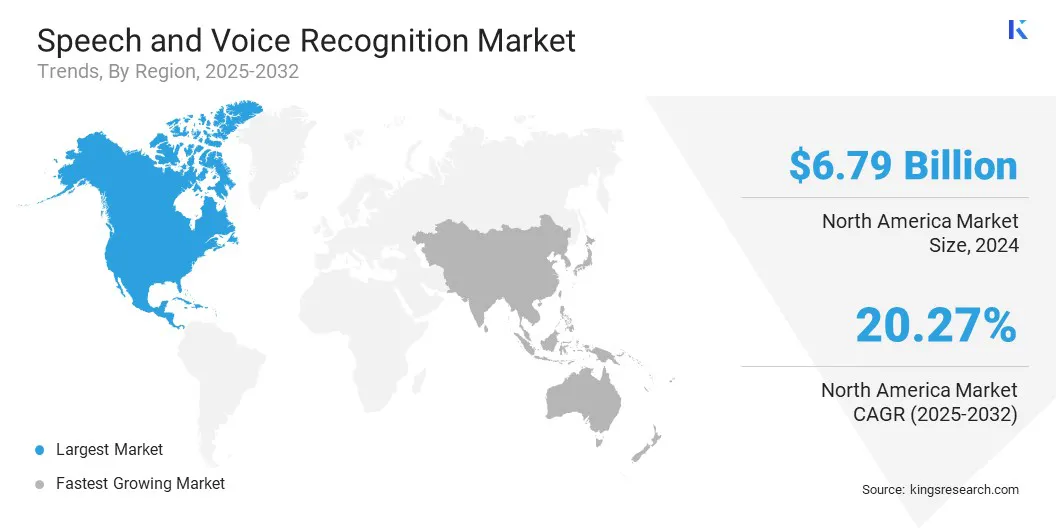
América del Norte mantuvo una participación del 35,95% en 2024, valorada en USD 6,79 mil millones.
El segmento de reconocimiento de voz obtuvo USD 10.18 mil millones en ingresos en 2024.
Se espera que el segmento basado en la nube llegue a USD 46.23 mil millones para 2032.
Se proyecta que el segmento de atención médica genere un ingreso de USD 14.11 mil millones para 2032.
Se anticipa que Asia Pacífico crece a una tasa compuesta anual del 21.31% durante el período de pronóstico.
Las principales empresas que operan en el reconocimiento del habla y la vozindustriason Apple Inc., Amazon.com, Inc., Alphabet Inc., Microsoft, IBM, Baidu, Iflytek Corporation, Samsung, Meta, Soundhound Ai Inc., Sensory Inc., Speechmatics, Verint Systems Inc., Cisco Systems, Inc. y OpenAI.
Las soluciones basadas en la voz mejoran la experiencia del usuario, la eficiencia operativa y la seguridad de los datos en el sector financiero al permitir interacciones naturales y manos libres que simplifican el acceso y las transacciones de las cuentas. Automatizan tareas de rutina, reduciendo la dependencia de los agentes humanos y menores costos de servicio. Además, el reconocimiento de voz proporciona autenticación biométrica, asegurando un acceso seguro a información confidencial y reforzando la confianza en la banca digital.
Por ejemplo, en abril de 2025, Omniwire, Inc. se asoció con Nowutalkai, Inc. para lanzar el primer banquero personal de AI Voice utilizando la tecnología "Voice to Action" de Nowutalkai. El asistente multilingüe de conversación se ofrece como una solución de etiqueta blanca para bancos, fintechs y cooperativas de crédito, que permite la banca segura y de voz a través de la plataforma bancaria como servicio basada en la nube de Omniwire.
Este desarrollo demuestra la integración de tecnologías de voz avanzadas en plataformas bancarias centrales que aborda la demanda de servicios financieros seguros, eficientes y fáciles de usar, lo que impulsa el crecimiento del mercado.
Conductor de mercado
Adopción creciente de asistentes virtuales con IA
El progreso del mercado global de reconocimiento de voz y voz se ve impulsado principalmente por la creciente integración de asistentes virtuales con IA en electrónica de consumo y dispositivos inteligentes.
A medida que las empresas y los hogares adoptanaltavoces inteligentes, teléfonos inteligentes y sistemas de información y entretenimiento en el automóvil, aumenta la demanda de interfaces de voz precisas y receptivas. Estos sistemas habilitados para AI mejoran la experiencia del usuario al permitir operaciones manos libres, recuperación de información eficiente y ejecución de tareas en tiempo real, fomentando la conveniencia y la accesibilidad.
La integración del procesamiento avanzado del lenguaje natural (PNL) y los algoritmos de aprendizaje automático permiten que estos sistemas comprendan el habla, acentos y comandos del usuario contextuales con alta precisión. Además, las empresas se centran en construir interfaces de voz más personalizadas y conscientes del contexto que se alinean con las expectativas de los usuarios en evolución. Esta creciente dependencia de las tecnologías basadas en la voz contribuye significativamente a la expansión del mercado.
En febrero de 2025, Amazon lanzó Alexa+, un asistente generativo de IA diseñado para interacciones de voz naturales e inteligentes. Integrado con LLMS Advanced, Alexa+ mejora la automatización de tareas, el control del hogar inteligente y la asistencia personalizada entre los dispositivos. Esta actualización tiene como objetivo ofrecer experiencias de conversación perfecta y en tiempo real.
Desafío del mercado
Acento y limitaciones contextuales en el reconocimiento de voz
Un desafío importante que impide el desarrollo del mercado de reconocimiento de voz y voz es la interpretación precisa de diversos acentos, dialectos y uso del lenguaje dependiente del contexto. Esto a menudo conduce a una precisión reducida, particularmente en entornos multilingües o entornos con altos niveles de ruido ambiental, lo que afecta la experiencia del usuario y la confiabilidad del sistema.
Para abordar este desafío, las empresas están desarrollando modelos avanzados de procesamiento del lenguaje natural (PNL) que incorporan técnicas de aprendizaje profundo y están capacitados en conjuntos de datos extensos y lingüísticamente diversos. Estos modelos están diseñados para mejorar la capacidad del sistema para reconocer las variaciones de voz matizadas y comprender la intención del usuario de manera más efectiva.
Además, las mejoras en la conciencia contextual están permitiendo a los sistemas interpretar mejor las señales de conversación, respaldar la accesibilidad más amplia y el rendimiento del mundo real.
En marzo de 2025, OpenAI presentó un nuevo conjunto de modelos de audio de próxima generación a través de su API, con capacidades de voz a texto y texto de última generación. Diseñado para una alta precisión y confiabilidad en condiciones acústicas desafiantes, el lanzamiento respalda el desarrollo de agentes de voz personalizables e inteligentes en diversas aplicaciones.
Tendencia de mercado
Integración del reconocimiento de voz en la industria de la salud
El mercado global de reconocimiento de voz y voz está influenciado por la integración de las tecnologías de IA de voz dentro de los sistemas de salud. Esta tendencia aumenta la adopción de herramientas avanzadas habilitadas para la voz que racionalizan los flujos de trabajo clínicos, reducen las cargas administrativas y mejoran la participación del paciente.
Integrar las capacidades de reconocimiento de voz enRegistro de salud electrónica (EHR)Las plataformas y los procesos de documentación clínica mejoran la precisión, aceleran la entrada de datos y aumenta la productividad del clínico.
La capacidad de estos sistemas para interpretar el lenguaje natural, apoyar la comunicación multilingüe y automatizar tareas repetitivas mejora significativamente la eficiencia operativa y la calidad del cuidado. Además, la creciente demanda de soluciones ambientales y manos libres en entornos de atención médica está fomentando la inversión continua en aplicaciones de salud con voz de voz, posicionando el reconocimiento del habla y la voz como un componente crítico en la transformación digital de los servicios de salud globales.
En marzo de 2025, Microsoft Corp. presentó Dragon Copilot, un asistente de voz con IA para flujos de trabajo clínicos. La solución integra Dragon Medical One y Dax Copilot para optimizar la documentación, automatizar tareas administrativas y mejorar la eficiencia del clínico. Construido en Microsoft Cloud for Healthcare, Dragon Copilot combina la escucha ambiental, el procesamiento del lenguaje natural y la IA generativa para mejorar el bienestar del proveedor y los resultados del paciente.
Informe del mercado de reconocimiento de voz y voz
Segmentación
Detalles
Por tecnología
Reconocimiento de voz, reconocimiento de voz
Por despliegue
Basado en la nube, en las instalaciones
Por vertical
Salud, TI y telecomunicaciones, automotriz, BFSI, gobierno y legal, educación, venta minorista, medios y entretenimiento, otros
Por región
América del norte: Estados Unidos, Canadá, México
Europa: Francia, Reino Unido, España, Alemania, Italia, Rusia, resto de Europa
Asia-Pacífico: China, Japón, India, Australia, ASEAN, Corea del Sur, resto de Asia-Pacífico
Medio Oriente y África: Turquía, U.A.E., Arabia Saudita, Sudáfrica, resto del Medio Oriente y África
Sudamerica: Brasil, Argentina, resto de América del Sur
Segmentación de mercado
Por tecnología (reconocimiento de voz y reconocimiento de voz): el segmento de reconocimiento de voz ganó USD 10.18 mil millones en 2024 debido a su adopción generalizada en asistentes virtuales, servicios de transcripción y automatización de servicios al cliente en todas las industrias.
Por despliegue (basado en la nube y en las instalaciones): el segmento basado en la nube tenía una participación de 57.37%en 2024, alimentada por su escalabilidad, facilidad de integración y menores costos de infraestructura inicial.
Por vertical (atención médica, TI y telecomunicaciones, automotriz, BFSI, gobierno y legal, educación, venta minorista, medios y entretenimiento, y otros): se proyecta que el segmento de atención médica alcance los USD 14.11 mil millones para 2032, debido al uso cada vez mayor de la documentación clínica habilitada por el habla y las herramientas de compromiso con voz de voz.
Análisis regional del mercado de reconocimiento de voz y voz
Basado en la región, el mercado se ha clasificado en América del Norte, Europa, Asia Pacífico, Medio Oriente y África y América del Sur.
El mercado de reconocimiento de voz y voz de América del Norte representó una participación sustancial de 35.95% en 2024, valorada en USD 6.79 mil millones. Este dominio se ve reforzado por una fuerte inversión en inteligencia artificial y tecnologías de procesamiento del lenguaje natural, que han avanzado significativamente las capacidades de los sistemas habilitados para la voz.
Estas innovaciones se integran cada vez más en la electrónica de consumo, el software empresarial y los servicios digitales, promoviendo experiencias de usuario sin problemas y manos libres. La disponibilidad de alta infraestructura digital, talento calificado y adopción de tecnología temprana acelera aún más esta tendencia.
Con la voz emergente como una interfaz principal para la interacción de dispositivos y aplicaciones, las empresas y consumidores norteamericanos están adoptando herramientas de reconocimiento de voz y voz, lo que solidifica la posición principal de la región.
En enero de 2025, Elevenlabs recaudó USD 180 millones en fondos de la Serie C para avanzar en su tecnología de audio de IA, ampliar su investigación y desarrollar nuevos productos que hacen que la voz y el sonido son centrales para las interacciones digitales.
El discurso de Asia y el reconocimiento de vozindustriaSe espera que registre la tasa compuesta anual más rápida del 21.31% durante el período de pronóstico. Este crecimiento se fomenta principalmente por la penetración en expansión de los teléfonos inteligentes y la integración de asistentes de voz en dispositivos móviles.
Con una gran y creciente población de usuarios móviles, especialmente en países como China, India y las naciones del sudeste asiático, existe una fuerte demanda de interacción de voz intuitiva y localizada. Los fabricantes y proveedores de servicios están integrando características de reconocimiento de voz para mejorar la accesibilidad, la comodidad del usuario y la personalización en idiomas y dialectos nativos.
Esta tendencia de la interfaz de voz centrada en el móvil está transformando la participación digital en sectores como el comercio electrónico, la banca, la atención médica y la educación. El aumento de los teléfonos inteligentes asequibles con capacidades de IA integradas alimenta aún más este crecimiento.
En diciembre de 2023, un*Instituto de Investigación de InfoComm, IMDA, y AI Singapur se asociaron para lanzar el primer modelo de lenguaje grande regional del sudeste asiático bajo el programa National Multimodal LLM de Singapur. La iniciativa tiene como objetivo desarrollar modelos culturalmente contextuales del habla -texto adaptados a los idiomas del sudeste asiático, mejorando las capacidades locales de interacción de voz.
Marcos regulatorios
En los EE. UU., La Comisión Federal de Comercio (FTC) y la Comisión Federal de Comunicaciones (FCC) regulan las tecnologías de voz bajo las leyes de protección y comunicación del consumidor, centrándose en la privacidad, la vigilancia y las prácticas comerciales justas.
En Europa, El Reglamento General de Protección de Datos (GDPR) rige la recopilación, el procesamiento y el almacenamiento de datos de voz, lo que requiere que las empresas garanticen la transparencia, el consentimiento del usuario y la minimización de datos al implementar tecnologías de reconocimiento de voz.
En China, La Administración del Ciberespacio de China (CAC) hace cumplir la Ley de Protección de Información Personal (PIPL), que incluye requisitos estrictos para datos biométricos como la voz, la garantía de almacenamiento de datos locales y el consentimiento de los usuarios.
En Japón, La Comisión de Protección de Información Personal (PPC) supervisa la Ley sobre la Protección de la Información Personal (APPI), que regula el uso de datos de voz, particularmente en aplicaciones que involucran autenticación biométrica o perfiles de voz.
Panorama competitivo
El reconocimiento global del habla y la vozindustriase caracteriza por una rápida innovación tecnológica, respaldada por la creciente integración de interfaces de voz en dispositivos cotidianos y soluciones empresariales.
Las empresas están colaborando activamente con las instituciones de investigación de IA y los proveedores de servicios en la nube para desarrollar conjuntamente aplicaciones avanzadas habilitadas para la voz, con el objetivo de ofrecer un procesamiento de voz más rápido, más preciso y consciente del contexto. Estas colaboraciones están permitiendo a las empresas mejorar las capacidades de análisis de voz y mejorar la capacidad de respuesta del sistema en diversos entornos, como centros de llamadas, automóviles y dispositivos inteligentes.
Las empresas están lanzando aún más plataformas de reconocimiento de voz especialmente diseñadas que se pueden integrar fácilmente en los flujos de trabajo empresariales, ofreciendo escalabilidad y adaptabilidad multilingüe. Este cambio continuo hacia la integración, la personalización y la optimización del rendimiento está intensificando la competencia, con los jugadores que se esfuerzan por diferenciarse a través de modelos patentados y soluciones de voz específicas de la región adaptadas a las necesidades del usuario.
En marzo de 2025, Kyndryl colaboró con Microsoft para lanzar Dragon Copilot, un asistente de salud con IA aprovechando la IA generativa para la escucha ambiental y el reconocimiento de voz. La asociación tiene como objetivo automatizar la documentación clínica, mejorar la eficiencia del médico y mejorar la atención al paciente mediante la integración de la dictado de voz y las capacidades del lenguaje natural en los flujos de trabajo de atención médica.
En septiembre de 2024, Deepgram lanzó su API de Agente de voz, una solución unificada de voz a voz que permite conversaciones en tiempo real y suena natural entre humanos y máquinas. La API integra el reconocimiento de voz avanzado y la síntesis de voz para ayudar a las empresas y desarrolladores a construir botes de voz inteligentes y agentes de IA para aplicaciones como la atención al cliente y el procesamiento de pedidos.
Empresas clave en el mercado de reconocimiento de voz y voz:
Desarrollos recientes (lanzamientos/colaboraciones de productos)
En abril de 2025, Aiola introdujo Jargonic, un modelo de base ASR diseñado para una transcripción en tiempo real específica de dominio utilizando manchas de palabras clave y aprendizaje de disparo cero. Jargonic ofrece un rendimiento superior en configuraciones industriales ruidosas, maneja el reconocimiento de voz multilingüe y supera a los competidores en la tasa de error de palabras y el retiro del término de jerga sin requerir el reentrenamiento para los nuevos vocabularios de la industria.
En abril de 2025, Kia amplió su sistema generativo de reconocimiento de voz con IA, Asistente de IA, al mercado europeo a través de actualizaciones por aire. Inicialmente introducido en Corea y Estados Unidos, el sistema permite la interacción natural y el control mejorado del vehículo, y estará disponible en modelos EV3 y otros modelos equipados con CCNC.
En abril de 2025, Intelepeer lanzó capacidades avanzadas de IA de voz con transmisión automática de reconocimiento de voz (ASR) y de texto a voz (TTS). Desarrollado internamente, la tecnología permite conversaciones en tiempo real, mejora la experiencia del cliente a través de interacciones naturales y baja latencia, y fortalece la plataforma de IA conversacional de extremo a extremo de la compañía con análisis mejorados, detección de idiomas y configuraciones de automatización personalizables.
En junio de 2024, Philips Speech by Speech Processing Solutions colaboró con Semly AI para lanzar tres nuevas grabadoras de audio integradas con la tecnología de IA. Los dispositivos ofrecen transcripciones automáticas, resúmenes, listas de acción y ideas, mientras que Semly AI agrega separación de altavoces, notas de reuniones y características de mejora de la productividad.
Preguntas frecuentes
¿Cuál es la CAGR esperada para el mercado de reconocimiento de voz y voz durante el período de pronóstico?
¿Qué tan grande era la industria en 2024?
¿Cuáles son los principales factores que impulsan el mercado?
¿Quiénes son los jugadores clave en el mercado?
¿Qué región se espera que sea la más rápida en el mercado durante el período de pronóstico?
¿Qué segmento se prevé que tenga la mayor parte del mercado en 2032?
Autor
Versha aporta más de 15 años de experiencia en la gestión de tareas de consultoría en industrias como la de alimentos y bebidas, bienes de consumo, TIC, aeroespacial y más. Su experiencia en múltiples dominios y su adaptabilidad la convierten en una profesional versátil y confiable. Con agudas habilidades analíticas y una mentalidad curiosa, Versha se destaca en transformar datos complejos en conocimientos prácticos. Tiene una trayectoria comprobada en desentrañar la dinámica del mercado, identificar tendencias y ofrecer soluciones personalizadas para satisfacer las necesidades de los clientes. Como líder cualificado, Versha ha asesorado con éxito a equipos de investigación y dirigido proyectos con precisión, garantizando resultados de alta calidad. Su enfoque colaborativo y su visión estratégica le permiten convertir los desafíos en oportunidades y ofrecer resultados impactantes de manera constante. Ya sea analizando mercados, involucrando a las partes interesadas o elaborando estrategias, Versha aprovecha su profunda experiencia y conocimiento de la industria para impulsar la innovación y ofrecer valor mensurable.
Con más de una década de liderazgo en investigación en mercados globales, Ganapathy aporta juicio agudo, claridad estratégica y profunda experiencia en la industria. Conocido por su precisión y compromiso inquebrantable con la calidad, guía a equipos y clientes con insights que impulsan consistentemente resultados empresariales impactantes.


 Mercado de reconocimiento de voz y voz
Mercado de reconocimiento de voz y voz