Marktgröße, Anteil, Wachstum und Branchenanalyse für die Generierung synthetischer Daten, nach Daten (Tabellendaten, Textdaten, Bild- und Videodaten, andere), nach Anwendung (Testdatenmanagement, KI-Schulung und -Entwicklung, Unternehmensdatenfreigabe, Datenanalyse und -visualisierung), nach Endbenutzer (Finanzdienstleistungen, Einzelhandel, Gesundheitswesen, andere) und regionale Analyse, 2026-2033
Seiten: 180 | Basisjahr: 2025 | Veröffentlichung: Februar 2026 | Autor: Ashim L. | Zuletzt aktualisiert: März 2026
Synthetische Daten sind künstliche Daten, die reale Daten nachahmen sollen. Es wird künstlich generiert, behält aber die statistischen Eigenschaften der Originaldaten bei, aus denen es generiert wurde. Die Generierung synthetischer Daten kann in Tabellen-, Multimedia- oder Textform erfolgen. Synthetische Textdaten können für die Verarbeitung natürlicher Sprache (NLP) nützlich sein. Ebenso finden tabellarische Daten Anwendung bei der Erstellung relationaler Datenbanktabellen.
Zu synthetischen Multimediainhalten gehören Bilder, Videos und andere unstrukturierte Daten, die unter anderem für Computer-Vision-Aufgaben wie Bilderkennung und Bildklassifizierung von entscheidender Bedeutung sein können. In Branchen wie dem Finanzwesen, dem Gesundheitswesen und dem Einzelhandel steigt der Datenbedarf. Synthetische Daten helfen solchen Organisationen, indem sie KI-Innovationen beschleunigen und intelligentere Entscheidungen ermöglichen.
Markt für synthetische DatengenerierungÜberblick
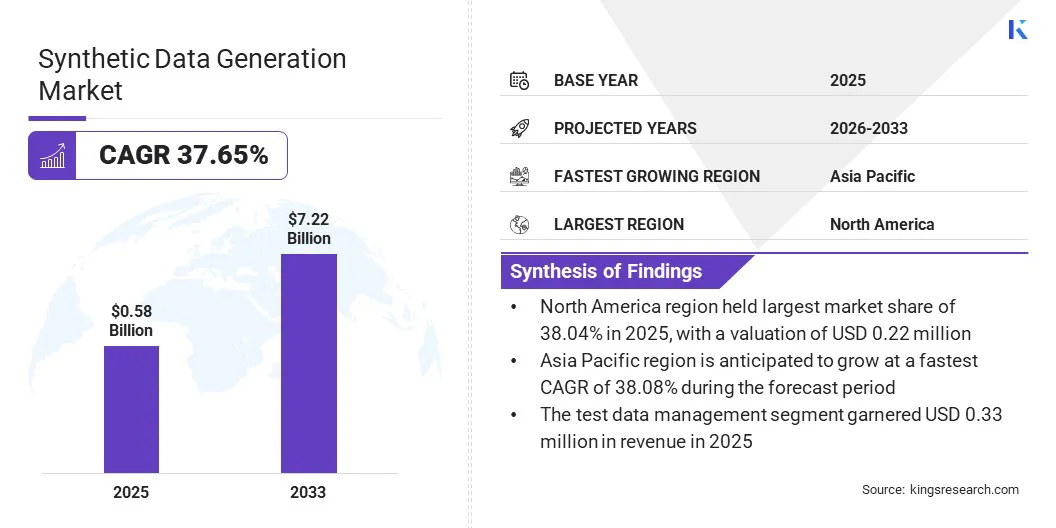
Die globale Marktgröße für die Generierung synthetischer Daten wurde im Jahr 2025 auf 0,58 Milliarden US-Dollar geschätzt und wird voraussichtlich von 0,77 Milliarden US-Dollar im Jahr 2026 auf 7,22 Milliarden US-Dollar im Jahr 2033 wachsen, was einer durchschnittlichen jährlichen Wachstumsrate von 37,65 % im Prognosezeitraum entspricht. Dieses Wachstum wird auf seine Anwendung für Testsysteme, das Training von KI-Modellen und die Simulation von Szenarien zurückgeführt, die im Allgemeinen schwer in realen Daten zu erfassen sind.
Im Gesundheitswesen können synthetische Krankenakten beispielsweise auf Erkrankungen wie Diabetes, Krankheiten oder Krebs hinweisen, was bei der Entwicklung und Erprobung von Diagnosetools sowie prädiktiven Gesundheitsmodellen hilfreich sein kann.
Zu den wichtigsten Unternehmen, die auf dem globalen Markt für die Generierung synthetischer Daten tätig sind, gehören unter anderem MOSTLY AI, Datagen, TonicAI, Inc., GenRocket, Inc, NVIDIA (Gretel Labs), K2view Ltd, CapGemini (Sogeti), CVEDIA Inc, Microsoft Corporation und MDClone.
Es wird erwartet, dass die Nachfrage nach synthetischen Daten mit der zunehmenden Verwendung in mehreren Sektoren, einschließlich der Automobilbranche zum Testen von, steigen wirdautonome Fahrzeuge, Gesundheitswesen für medizinische Bildanalyse und Patientendiagnose. Im Einzelhandel wird es vor allem für das Investmentmanagement und die Analyse des Kundenverhaltens eingesetzt.
Dies kann im Finanzwesen bei der Aufdeckung von Betrug und der Risikobewertung von Vorteil sein. Der Hauptvorteil synthetischer Daten liegt in der Kosteneffizienz, Skalierbarkeit und Vielfalt. Diese werden hauptsächlich zum Trainieren von Modellen für maschinelles Lernen verwendet. Es bietet eine bessere Kontrolle über die Datenqualität und schützt außerdem die Privatsphäre, indem die Verwendung echter, sensibler Daten entfällt.
Der jüngste Trend deutet auf die Integration von föderiertem Lernen und differenziellem Datenschutz hin, um das maschinelle Lernen zur Wahrung der Privatsphäre zu verbessern. Außerdem wird die Nachfrage nach vielfältigen und qualitativ hochwertigen Trainingsdatensätzen mit der Ausweitung der KI in neue Bereiche wachsen, wodurch synthetische Daten sehr wichtig werden.
Wichtigste Highlights:
Die globale Marktgröße für die Generierung synthetischer Daten belief sich im Jahr 2025 auf 0,58 Milliarden US-Dollar.
Der Markt soll von 2026 bis 2033 mit einer jährlichen Wachstumsrate von 37,65 % wachsen.
Nordamerika hatte im Jahr 2025 einen Anteil von 38,04 % im Wert von 0,22 Milliarden US-Dollar.
Das Segment der tabellarischen Daten erwirtschaftete im Jahr 2025 einen Umsatz von 0,20 Milliarden US-Dollar.
Das Segment Testdatenmanagement wird bis 2033 voraussichtlich 4,05 Milliarden US-Dollar erreichen.
Es wird erwartet, dass das Gesundheitssegment im Prognosezeitraum die schnellste CAGR von 38,28 % verzeichnen wird.
Der asiatisch-pazifische Raum wird im Prognosezeitraum voraussichtlich mit einer jährlichen Wachstumsrate von 38,08 % wachsen.
Wie zuverlässig sind synthetische Daten für das KI-Training?
Wenn synthetische Daten mit robusten Techniken generiert werden, können sie hinsichtlich der Modellleistung mit den realen Daten mithalten oder diese in manchen Fällen sogar übertreffen, insbesondere bei seltenen Ereignissen.
Obwohl es die realen Daten nicht ersetzen kann, ist es bei der Unterstützung der realen Daten sehr effektiv, insbesondere wenn das Team mit begrenzten Daten, unausgewogenen Datensätzen oder Datenschutzbeschränkungen zu tun hat. Dadurch kann es als leistungsstarke Ergänzung zu realen Daten dienen und nicht als vollständiger Ersatz.
Im Oktober 2024 stellte MOSTLY AI seine neue Funktion für synthetischen Text zum Training von KI-Modellen vor und kümmert sich auch um den Datenschutz proprietärer Datenbestände. Es hilft dem Unternehmen, eine breite Palette von Textdaten wie E-Mails, Chatbot-Gespräche, Kundensupport-Transkripte usw. für die Schulung und Feinabstimmung zu nutzengroße Sprachmodelle (LLMs), und es besteht kein Risiko einer Datenschutzverletzung.
Warum erfordert das Training von KI-Systemen das Bewusstsein, dass synthetische Daten zu falschen Ergebnissen führen können?
Synthetischen Daten fehlen möglicherweise die Komplexität und Nuancen realer Daten, was dazu führen kann, dass KI-Modelle in realen Szenarien eine schlechte Leistung erbringen. Darüber hinaus besteht die Möglichkeit, dass KI-Modelle, die vollständig auf synthetischen Daten trainiert sind, aufgrund der Unterschiede zwischen synthetischen und tatsächlichen Daten nicht effektiv auf reale Situationen übertragen werden können. Bei einigen Anwendungen, beispielsweise bei der medizinischen Diagnose, könnte dies auch ethische Bedenken aufwerfen.
Wie bietet die Generierung synthetischer Daten geschäftliche Vorteile hinsichtlich Kosten und Skalierbarkeit?
Die Erfassung realer Daten ist aufgrund der Verknüpfung von Sensoreinsatz, Kennzeichnung und Sicherheit kostspielig und langsam. Aber die synthetischen Daten für das maschinelle Online-Lernen können einfacher, kostengünstiger und schneller generiert werden. Synthetische Daten bieten kontrollierte und skalierbare Datenquellen für eine robuste Entwicklung von KI. Beispielsweise bieten Organisationen wie Nvidia und Databricks Tools wie Unity Catalog und Omniverse Replicator zur Automatisierung synthetischer Datenpipelines an. Schätzungen zufolge sind etwa 50 bis 60 % der für das Training von KI-Plattformen verwendeten Daten synthetisch. Die Nachfrage steigt, da es Unternehmen dabei hilft, neue Produkte zu simulieren, die Entwicklung von KI-Modellen zu beschleunigen und vertrauliche Informationen zu schützen.
Im Oktober 2025 kündigte GenRocket die Einführung seines Unstructured Data Accelerator (UDA) an, der das designorientierte Unternehmen zur Generierung synthetischer Daten dazu veranlasste, seine Plattform über strukturierte Daten hinaus auf Bilder, Dokumente und dateibasierte Formate zu erweitern. Es hat dem Unternehmen dabei geholfen, jede Art von Daten sicher, präzise und bedarfsgerecht in großem Maßstab zu generieren.
Schnappschuss des Marktberichts zur Generierung synthetischer Daten
Segmentierung
Einzelheiten
Nach Daten
Tabellendaten, Textdaten, Bild- und Videodaten, Sonstiges
Auf Antrag
Testdatenmanagement, KI-Schulung und -Entwicklung, Unternehmensdatenfreigabe, Datenanalyse und -visualisierung
Vom Endbenutzer
Finanzdienstleistungen, Einzelhandel, Gesundheitswesen und andere
Nach Region
Nordamerika: USA, Kanada, Mexiko
Europa: Frankreich, Großbritannien, Spanien, Deutschland, Italien, Russland, übriges Europa
Nach Daten (Tabellendaten, Textdaten, Bild- und Videodaten und andere): Das Tabellendatensegment generierte im Jahr 2025 einen Umsatz von 0,20 Milliarden US-Dollar, hauptsächlich aufgrund seiner zunehmenden Akzeptanz im E-Commerce- und Gesundheitssektor. Es wird hauptsächlich zum effektiven Training einiger Modelle des maschinellen Lernens verwendet.
Nach Anwendung (Testdatenmanagement, KI-Schulung und -Entwicklung, gemeinsame Nutzung von Unternehmensdaten sowie Datenanalyse und -visualisierung): Das Segment KI-Schulung und -Entwicklung dürfte im Prognosezeitraum eine erstaunliche CAGR von 38,08 % verzeichnen, was auf den breiten Bedarf an der Schulung von Modellen für maschinelles Lernen zurückzuführen ist. Es dient als potenzielle Lösung für Szenarien, in denen Daten benötigt werden, aber nur ein Mangel an hochwertigen realen Daten für das Training von KI-Modellen vorhanden ist.
Nach Endbenutzern (Finanzdienstleistungen, Einzelhandel, Gesundheitswesen und andere): Der Anteil des Finanzdienstleistungssegments wird bis 2032 schätzungsweise 32,13 % betragen, angetrieben durch die Vorteile synthetischer Daten wie sichere Datenfreigabe und Modellentwicklung für Risikobewertung, Betrugserkennung und Analyse, ohne die tatsächlichen Kundeninformationen preiszugeben. Für seltene Ereignisse wie Marktabstürze oder komplexe Betrugsformen kann die Generierung synthetischer Daten möglich sein, was dazu beiträgt, die Modellleistung zu verbessern und die KI-Entwicklung zu beschleunigen.
Wie sieht das Marktszenario in Nordamerika und im asiatisch-pazifischen Raum aus?
Basierend auf der Region wurde der globale Markt für die Generierung synthetischer Daten in Nordamerika, Europa, den asiatisch-pazifischen Raum, den Nahen Osten und Afrika sowie Südamerika unterteilt.
Der nordamerikanische Markt für die Generierung synthetischer Daten hatte im Jahr 2025 einen Anteil von 38,04 % und einen Wert von 0,22 Milliarden US-Dollar. Diese Dominanz wird auf eine Kombination aus fortschrittlicher technologischer Infrastruktur und höheren Investitionen in Forschung und Entwicklung in der Region zurückgeführt. Insbesondere in den USA setzen Unternehmen neueste Technologien ein, um Risiken und Ineffizienz zu verringern.
Darüber hinaus bevorzugen Verbraucher Marken, die sich auf inkrementelle Innovationen konzentrieren. Im Einzelhandel hilft die Generierung synthetischer Daten bei der Analyse von Kundenpräferenzen wie Einkaufsgewohnheiten und saisonaler Nachfrage und schützt gleichzeitig die Privatsphäre. Die Region hat wachsende Datenschutzverpflichtungen und ein starkes KI-Ökosystem, was ein günstiges Umfeld für das Wachstum des Marktes schafft.
Im Juni 2021 kündigte CVEDIA eine Lösung für die Domain-Akzeptanzlücke mithilfe der proprietären synthetischen Datenpipeline an. Sie können bei der Entwicklung von KI helfen, indem sie es ermöglichen, dass Algorithmen, die auf synthetischen Daten trainiert wurden, genauso gut funktionieren wie Algorithmen, die auf realen Daten trainiert wurden. CVEDIA behauptete eine Präzisionsverbesserung von 170 % und einen nachhaltigen Zuwachs von 160 % bei der Erinnerung im Vergleich zu Benchmark-Modellen.
Der Markt für die Generierung synthetischer Daten im asiatisch-pazifischen Raum wird im Prognosezeitraum voraussichtlich mit einer jährlichen Wachstumsrate von 38,08 % wachsen. Dieses bemerkenswerte Wachstum wird durch die zunehmende Nutzung synthetischer Daten in mehreren Bereichen der Region unterstützt, beispielsweise im Gesundheitswesen, im verarbeitenden Gewerbe usw.
Beispielsweise werden im Gesundheitswesen synthetische Daten generiert, um realistische Patientenakten zu erstellen, die die Forschung unterstützen und gleichzeitig Anonymisierung und Aggregation ermöglichen. Es unterstützt medizinische Forscher bei der Entwicklung und Erprobung von Algorithmen für Diagnose und Behandlung unter Einhaltung strenger Datenschutzbestimmungen.
In der Fertigung nutzen die Automobilkonzerne synthetische Daten, um verschiedene Fahrszenarien für die autonomen Autos zu simulieren. Es hilft beim Training von Modellen für maschinelles Lernen zum Erkennen und Reagieren auf verschiedene Bedingungen, ohne dass eine umfangreiche Erfassung realer Daten erforderlich ist. Unternehmen wie Waymo und Tesla revolutionieren die Nutzung synthetischer Daten zum Training ihrer selbstfahrenden Autos.
Regulatorische Rahmenbedingungen
Die Datenschutz-Grundverordnung (DSGVO) regelt die Verarbeitung personenbezogener Daten in der EU und definiert, was als anonymisierte oder synthetische Daten gilt.
Der Data (Use and Access) Act 2025 im Vereinigten Königreich regelt die Bestimmungen im Zusammenhang mit der Verarbeitung und dem Zugriff auf persönliche und geschäftliche Daten. Es aktualisiert den bestehenden Rahmen der britischen DSGVO und des Datenschutzgesetzes.
In den Vereinigten Staaten (Kalifornien) regeln der California Consumer Privacy Act (CCPA) und seine Ergänzung, der California Privacy Rights Act (CPRA), die Erhebung und Nutzung personenbezogener Daten.
Wettbewerbslandschaft
Die wichtigsten Akteure auf dem Markt für die Generierung synthetischer Daten konzentrieren sich weitgehend auf kontinuierliche technologische Innovation. Es gibt viele kleine und mittelgroße Anbieter, die auf bestimmte Datentypen und Sektoren abzielen. Die Spezialanbieter haben keinen dominanten Marktanteil und agieren in Nischensegmenten.
Große Cloud- und KI-Plattformen wie Microsoft und NVIDIA nehmen unter anderem einen wichtigen Marktanteil ein, da synthetische Datenfunktionen in umfassenderen KI- und ML-Diensten vorhanden sind. Der Fokus liegt auch auf Partnerschaften und Akquisitionen zur Erzielung strategischer Vorteile.
Im März 2025 erwarb Nvidia für mehr als 320 Millionen US-Dollar Gretel, ein Startup für synthetische Daten, das seine Suite generativer KI-Dienste für Entwickler unterstützt. Gretel unterhält Partnerschaften mit großen Cloud-Anbietern wie Google Cloud, Amazon Web Services und Microsoft.
Wichtige Unternehmen im Markt für synthetische Datengenerierung:
Im April 2023 gab MDClone bekannt, dass seine ADAMS-Plattform mehr Partnerschaften zwischen Gesundheitsdienstleistern und Biowissenschaftsunternehmen ermöglicht, um die therapeutische Forschung und Entwicklung zu beschleunigen.
Häufig gestellte Fragen
Was sind die Haupttreiber im Markt für synthetische Datengenerierung?
Welche Regionen sind für das Wachstum der synthetischen Datengenerierung von zentraler Bedeutung?
Vor welchen Herausforderungen steht die Branche der synthetischen Datengenerierung heute?
Welche Trends prägen die Zukunft der synthetischen Datengenerierung?
Wer sind die Hauptakteure in diesem Sektor?
Welche Möglichkeiten bestehen für Investoren?
Wie hilft mir dieser Bericht, unsere Wachstumsstrategie auf die vielversprechendste geografische Region zu konzentrieren?
Wie hilft mir dieser Bericht zu verstehen, welche Datenkategorie die größten wirtschaftlichen Auswirkungen hat?
Autor
Ashim betreut syndizierte und maßgeschneiderte Market-Intelligence-Projekte vom Entwurf bis zur Lieferung. Er ist spezialisiert auf Marktinformationen, Wachstumsmodellierung, Wettbewerbsstrategie und Entscheidungsunterstützung für Führungskräfte. Sein Führungsansatz legt Wert auf klares Denken und messbare geschäftliche Auswirkungen.
Mit über einem Jahrzehnt Forschungserfahrung in globalen Märkten bringt Ganapathy scharfsinniges Urteilsvermögen, strategische Klarheit und tiefes Branchenwissen mit. Bekannt für Präzision und unerschütterliches Engagement für Qualität, führt er Teams und Kunden mit Erkenntnissen, die konsequent zu wirkungsvollen Geschäftsergebnissen führen.