Marché de la reconnaissance de la parole et de la voix
Marché de la reconnaissance de la parole et de la voix
La taille du marché de la parole et de la reconnaissance vocale, la part, la croissance et l'analyse de l'industrie, par technologie (reconnaissance de la parole, reconnaissance vocale), par déploiement (basé sur le cloud, sur site), par vertical (soins de santé, informatique et télécommunications, automobile, BFSI, gouvernement et juridique, éducation, vente au détail, médias et divertissement, autres) et une analyse régionale, 2025-2032
Pages: 170 | Année de base: 2024 | Version: July 2025 | Auteur: Versha V. | Dernière mise à jour: July 2025
La reconnaissance vocale fait référence à la capacité technologique de convertir le langage parlé en texte écrit, tandis que la reconnaissance vocale implique d'identifier les individus basés sur des caractéristiques vocales distinctes. Le marché englobe le matériel, les logiciels et les services qui interprètent et traitent la parole humaine.
Les applications clés incluent des assistants virtuels, une transcription automatisée, des systèmes vocaux intégrés et une authentification biométrique. Ces technologies sont utilisées dans diverses industries telles que les soins de santé, la finance, le commerce de détail et l'entreprise pour l'exécution des commandes et la vérification sécurisée des utilisateurs.
Présentation du marché de la reconnaissance de la parole et de la voix
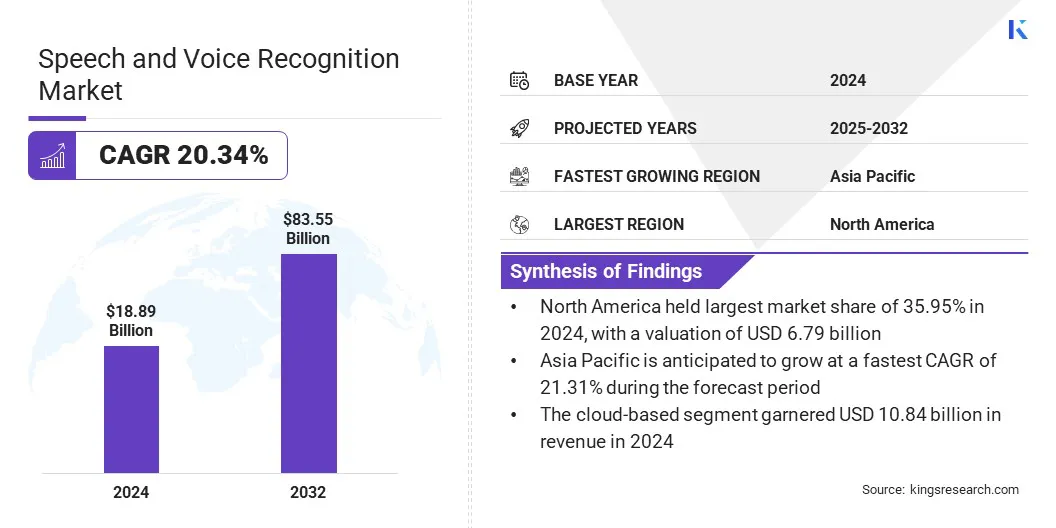
La taille mondiale du marché de la reconnaissance de la parole et de la reconnaissance vocale était évaluée à 18,89 milliards USD en 2024 et devrait passer de 22,65 milliards USD en 2025 à 83,55 milliards USD d'ici 2032, présentant un TCAC de 20,34% au cours de la période de prévision.
Le marché connaît une croissance significative, tirée par l'intégration croissante des technologies vocales à travers l'électronique grand public, les systèmes automobiles et les applications d'entreprise. L'adoption accrue des assistants intelligents, les progrès du traitement du langage naturel et la demande croissante d'interfaces sans contact alimentent l'expansion du marché.
Faits saillants clés
La taille de l'industrie de la reconnaissance de la parole et de la voix était évaluée à 18,89 milliards USD en 2024.
Le marché devrait croître à un TCAC de 20,34% de 2025 à 2032.
L'Amérique du Nord a détenu une part de 35,95% en 2024, évaluée à 6,79 milliards USD.
Le segment de la reconnaissance vocale a récolté 10,18 milliards de dollars de revenus en 2024.
Le segment basé sur le cloud devrait atteindre 46,23 milliards USD d'ici 2032.
Le segment des soins de santé devrait générer un chiffre d'affaires de 14,11 milliards USD d'ici 2032.
L'Asie-Pacifique devrait croître à un TCAC de 21,31% au cours de la période de prévision.
Les grandes entreprises opérant dans le discours et la reconnaissance vocaleindustriesont Apple Inc., Amazon.com, Inc., Alphabet Inc., Microsoft, IBM, Baidu, Iflytek Corporation, Samsung, Meta, Soundhound AI Inc., Sensory Inc., Speechmatics, Verint Systems Inc., Cisco Systems, Inc. et Openai.
Les solutions vocales améliorent l'expérience utilisateur, l'efficacité opérationnelle et la sécurité des données dans le secteur financier en permettant des interactions naturelles et mains libres qui simplifient l'accès et les transactions du compte. Ils automatisent les tâches de routine, réduisant la dépendance à l'égard des agents humains et réduisent les coûts de service. De plus, la reconnaissance vocale fournit une authentification biométrique, garantissant un accès sécurisé aux informations sensibles et renforçant la confiance dans la banque numérique.
Par exemple, en avril 2025, Omniwire, Inc. s'est associé à Nowutalkai, Inc. pour lancer le premier banquier personnel de l'IA Voice en utilisant la technologie «Voice to Action» de Nowutalkai. L'assistant multilingue et conversationnel est proposé en tant que solution de marque blanche pour les banques, les fintechs et les coopératives de crédit, permettant une banque sécurisée et axée sur la voix via la plate-forme bancaire basée sur le cloud d'Omniwire.
Cette évolution démontre que l'intégration des technologies vocales avancées dans les plates-formes bancaires de base répond à la demande de services financiers sécurisés, efficaces et conviviaux, stimulant ainsi la croissance du marché.
Moteur du marché
Adoption croissante d'assistants virtuels alimentés par l'IA
Les progrès du marché mondial de la reconnaissance de la parole et de la voix sont principalement alimentés par l'intégration croissante des assistants virtuels alimentés par l'IA dans l'électronique grand public et les appareils intelligents.
Comme les entreprises et les ménages adoptenthaut-parleurs intelligents, smartphones et systèmes d'infodivertissement dans la voiture, la demande d'interfaces vocales précises et réactives augmente. Ces systèmes compatibles AI améliorent l'expérience utilisateur en permettant des opérations mains libres, une récupération efficace des informations et une exécution des tâches en temps réel, en favorisant la commodité et l'accessibilité.
L'intégration du traitement avancé du langage naturel (NLP) et des algorithmes d'apprentissage automatique permet à ces systèmes de comprendre la parole contextuelle, les accents et les commandes utilisateur avec une grande précision. De plus, les entreprises se concentrent sur la création d'interfaces vocales plus personnalisées et pluscieuses qui s'alignent sur l'évolution des attentes des utilisateurs. Cette dépendance croissante à l'égard des technologies vocales contribue considérablement à l'expansion du marché.
En février 2025, Amazon a lancé Alexa +, un assistant génératif alimenté par l'IA conçu pour les interactions vocales naturelles et intelligentes. Intégrée aux LLM avancées, Alexa + améliore l'automatisation des tâches, le contrôle des maisons intelligentes et l'assistance personnalisée entre les appareils. Cette mise à niveau vise à offrir des expériences conversationnelles sans couture et en temps réel.
Défi du marché
Accent et limitations contextuelles de la reconnaissance vocale
Un défi majeur entravant le développement du marché de la reconnaissance de la parole et de la voix est l'interprétation précise des accents divers, des dialectes et de l'utilisation du langage dépendante du contexte. Cela conduit souvent à une précision réduite, en particulier dans les paramètres multilingues ou les environnements avec des niveaux de bruit ambiants élevés, affectant l'expérience utilisateur et la fiabilité du système.
Pour relever ce défi, les entreprises développent des modèles avancés de traitement du langage naturel (NLP) qui intègrent des techniques d'apprentissage en profondeur et sont formés à des ensembles de données étendus et linguistiques. Ces modèles sont conçus pour améliorer la capacité du système à reconnaître les variations de la parole nuancées et à comprendre l'intention des utilisateurs plus efficacement.
En outre, les améliorations de la conscience contextuelle permettent aux systèmes d'interpréter des indices conversationnels, soutenant une accessibilité plus large et des performances réelles.
En mars 2025, Openai a présenté une nouvelle suite de modèles audio de nouvelle génération via son API, avec des capacités de parole à la parole et de texte vocale à la pointe de la technologie. Conçu pour une grande précision et une fiabilité dans des conditions acoustiques difficiles, la version soutient le développement d'agents vocaux personnalisables et intelligents à travers diverses applications.
Tendance
Intégration de la reconnaissance vocale dans l'industrie des soins de santé
Le marché mondial de la reconnaissance de la parole et de la voix est influencé par l'intégration des technologies de l'IA Voice dans les systèmes de santé. Cette tendance stimule l'adoption d'outils avancés à la voix qui rationalisent les flux de travail cliniques, réduisent les charges administratives et améliorent l'engagement des patients.
Intégrer les capacités de reconnaissance de la parole dansDossier de santé électronique (DSE)Les plateformes et les processus de documentation clinique améliorent la précision, accélère la saisie des données et stimule la productivité des cliniciens.
La capacité de ces systèmes à interpréter le langage naturel, à soutenir la communication multilingue et à automatiser les tâches répétitives améliore considérablement l'efficacité opérationnelle et la qualité des soins. En outre, la demande croissante de solutions ambiantes et mains libres dans les établissements de soins de santé favorise les investissements continus dans les applications de soins de santé compatibles avec la voix, le positionnement de la parole et la reconnaissance vocale comme un élément essentiel de la transformation numérique des services de santé mondiaux.
En mars 2025, Microsoft Corp. a présenté Dragon Copilot, un assistant vocal alimenté par l'IA pour les workflows cliniques. La solution intègre Dragon Medical One et Dax Copilot pour rationaliser la documentation, automatiser les tâches administratives et améliorer l'efficacité du clinicien. Construit sur Microsoft Cloud pour les soins de santé, Dragon Copilot combine l'écoute ambiante, le traitement du langage naturel et l'IA génératrice pour améliorer le bien-être des prestataires et les résultats pour les patients.
Rapport sur le marché de la reconnaissance de la parole et de la voix
Segmentation
Détails
Par technologie
Reconnaissance de la parole, reconnaissance vocale
Par déploiement
Basé sur le cloud, sur site
Par vertical
Santé, TI et télécommunications, automobile, BFSI, gouvernement et juridique, éducation, vente au détail, médias et divertissement, autres
Par région
Amérique du Nord: États-Unis, Canada, Mexique
Europe: France, Royaume-Uni, Espagne, Allemagne, Italie, Russie, reste de l'Europe
Asie-Pacifique: Chine, Japon, Inde, Australie, ASEAN, Corée du Sud, reste de l'Asie-Pacifique
Moyen-Orient et Afrique: Turquie, U.A.E., Arabie saoudite, Afrique du Sud, reste du Moyen-Orient et de l'Afrique
Amérique du Sud: Brésil, Argentine, reste de l'Amérique du Sud
Segmentation du marché
Par technologie (reconnaissance vocale et reconnaissance vocale): Le segment de reconnaissance vocale a gagné 10,18 milliards USD en 2024 en raison de son adoption généralisée dans les assistants virtuels, les services de transcription et l'automatisation du service client dans toutes les industries.
Par déploiement (basé sur le cloud et sur site): le segment basé sur le cloud détenait une part de 57,37% en 2024, alimentée par son évolutivité, sa facilité d'intégration et ses coûts d'infrastructure initiale inférieurs.
Par vertical (Healthcare, It & Telecommunications, Automotive, BFSI, Government & Legal, Education, Retail, Media & Entertainment et autres): Le segment des soins de santé devrait atteindre 14,11 milliards de dollars d'USD d'ici 2032, en raison de l'utilisation croissante de la documentation clinique renforcée par la parole et des outils d'engagement vocal.
Analyse régionale du marché de la reconnaissance de la parole et de la parole
Sur la base de la région, le marché a été classé en Amérique du Nord, en Europe, en Asie-Pacifique, au Moyen-Orient et en Afrique et en Amérique du Sud.
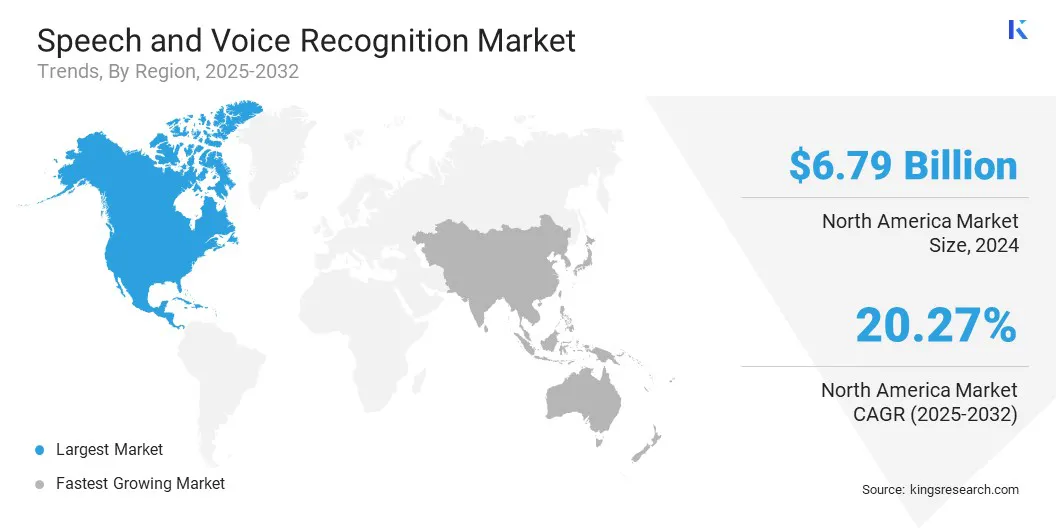
Le marché de la parole et de la reconnaissance vocale en Amérique du Nord a représenté une part substantielle de 35,95% en 2024, évaluée à 6,79 milliards USD. Cette domination est renforcée par un fort investissement dans l'intelligence artificielle et les technologies de traitement du langage naturel, qui ont considérablement avancé les capacités des systèmes à la voix.
Ces innovations sont de plus en plus intégrées dans l'électronique grand public, les logiciels d'entreprise et les services numériques, favorisant des expériences utilisateur sans couture et mains libres. La disponibilité d'une infrastructure numérique élevée, des talents qualifiés et de l'adoption des technologies précoces accélère encore cette tendance.
La voix émergeant comme une interface principale pour l'interaction des appareils et des applications, les entreprises et les consommateurs nord-américains adoptent des outils de reconnaissance de la parole et de la voix, solidifiant la position principale de la région.
En janvier 2025, ElevenLabs a levé 180 millions USD dans le financement de la série C pour faire avancer sa technologie audio AI, élargir ses recherches et développer de nouveaux produits qui rendent la voix et le son cœur des interactions numériques.
La parole Asie-Pacifique et la reconnaissance vocaleindustriedevrait enregistrer le TCAC le plus rapide de 21,31% au cours de la période de prévision. Cette croissance est principalement favorisée par l'expansion de la pénétration des smartphones et l'intégration des assistants vocaux dans les appareils mobiles.
Avec une population importante et croissante d'utilisateurs mobiles, en particulier dans des pays comme la Chine, l'Inde et les nations d'Asie du Sud-Est, il existe une forte demande d'interaction vocale intuitive et localisée. Les fabricants et les fournisseurs de services intégrent les fonctionnalités de reconnaissance vocale pour améliorer l'accessibilité, la commodité des utilisateurs et la personnalisation dans les langues natives et les dialectes.
Cette tendance d'interface vocale centrée sur le mobile transforme l'engagement numérique entre les secteurs tels que le commerce électronique, la banque, les soins de santé et l'éducation. La montée des smartphones abordables avec des capacités d'IA intégrées alimente cette croissance.
En décembre 2023, l’Institut pour la recherche Infocomm de * Star’s Infocomm, IMDA et l’IA Singapour s’est associé pour lancer le premier modèle régional de grande langue en Asie du Sud-Est dans le cadre du programme national Multimodal LLM de Singapour. L'initiative vise à développer des modèles de texte de parole culturellement contextuels adaptés aux langues d'Asie du Sud-Est, améliorant les capacités d'interaction vocale locales.
Cadres réglementaires
Aux États-Unis, la Federal Trade Commission (FTC) et la Federal Communications Commission (FCC) réglementent les technologies vocales en vertu des lois sur la protection des consommateurs et les communications, en se concentrant sur la confidentialité, la surveillance et les pratiques commerciales équitables.
En Europe, le règlement général sur la protection des données (RGPD) régit la collecte, le traitement et le stockage des données vocales, obligeant les entreprises à assurer la transparence, le consentement des utilisateurs et la minimisation des données lors du déploiement des technologies de reconnaissance vocale.
En Chine, l'administration du cyberespace de la Chine (CAC) applique la loi sur la protection des informations personnelles (PIPL), qui comprend des exigences strictes pour les données biométriques telles que la voix, l'assurance de stockage des données locales et le consentement des utilisateurs.
Au Japon, la Commission de protection de l'information personnelle (PPC) supervise la loi sur la protection des informations personnelles (APPI), qui réglemente l'utilisation des données vocales, en particulier dans les applications impliquant l'authentification biométrique ou le profilage vocal.
Paysage compétitif
La reconnaissance mondiale de la parole et de la voixindustrieest caractérisé par une innovation technologique rapide, soutenue par l'intégration croissante des interfaces vocales dans les appareils quotidiens et les solutions d'entreprise.
Les entreprises collaborent activement avec les institutions de recherche sur l'IA et les fournisseurs de services cloud pour co-développer des applications vocales avancées, visant à offrir un traitement de la parole plus rapide, plus précis et contextuel. Ces collaborations permettent aux entreprises d'améliorer les capacités d'analyse vocale et d'améliorer la réactivité du système dans divers environnements tels que les centres d'appels, les automobiles et les appareils intelligents.
Les entreprises lancent en outre des plateformes de reconnaissance vocale spécialement conçues qui peuvent être facilement intégrées dans les workflows d'entreprise, offrant l'évolutivité et l'adaptabilité multilingue. Ce changement continu vers l'intégration, la personnalisation et l'optimisation des performances intensifie la concurrence, les joueurs s'efforçant de se différencier à travers des modèles propriétaires et des solutions vocales spécifiques à la région adaptées aux besoins des utilisateurs.
En mars 2025, Kyndryl a collaboré avec Microsoft pour lancer Dragon Copilot, un assistant de santé alimenté par l'IA en tirant parti de l'IA générative pour l'écoute ambiante et la reconnaissance vocale. Le partenariat vise à automatiser la documentation clinique, à améliorer l'efficacité des cliniciens et à améliorer les soins aux patients en intégrant la dictée vocale et les capacités du langage naturel dans les flux de travail des soins de santé.
En septembre 2024, Deepgram a lancé son API vocal Agent, une solution de voix à voix unifiée permettant des conversations à consonance naturelle en temps réel entre les humains et les machines. L'API intègre la reconnaissance vocale avancée et la synthèse vocale pour aider les entreprises et les développeurs à créer des bots de voix intelligents et des agents d'IA pour des applications telles que le support client et le traitement des commandes.
Les principales entreprises du marché de la reconnaissance de la parole et de la voix:
Développements récents (lancements de produits / collaborations)
En avril 2025, AIOLA a introduit Jargonic, un modèle ASR de base conçu pour la transcription spécifique au domaine en temps réel en utilisant des taches de mots clés et un apprentissage zéro-shot. Jargonic offre des performances supérieures dans des contextes industriels bruyants, gère la reconnaissance de la parole multilingue et surpasse les concurrents dans le taux d'erreur de mots et le rappel de termes de jargon sans nécessiter de recyclage pour de nouveaux vocabulaires de l'industrie.
En avril 2025, Kia a élargi son système de reconnaissance vocale génératif alimenté par l'IA, AIDE ASSISTANT, au marché européen via des mises à jour en direct. Initialement introduit en Corée et aux États-Unis, le système permet une interaction naturelle et un contrôle amélioré des véhicules, et sera disponible sur les modèles EV3 et d'autres modèles équipés de CCNC.
En avril 2025, Intelepeer a lancé des capacités avancées d'IA vocale présentant une reconnaissance vocale automatique (ASR) et un streaming de texte à dispection (TTS). Développé en interne, la technologie permet des conversations en temps réel, améliore l'expérience client grâce à des interactions naturelles et à une faible latence, et renforce la plate-forme d'IA conversationnelle de bout en bout de l'entreprise avec une analyse améliorée, une détection du langage et des paramètres d'automatisation personnalisables.
En juin 2024, Philips Speech by Speech Processing Solutions a collaboré avec SEMNMING IA pour lancer trois nouveaux enregistreurs audio intégrés à la technologie de l'IA. Les appareils offrent des transcriptions, des résumés, des listes d'action et des informations automatiques, tandis que SEMMY IA ajoute la séparation des haut-parleurs, les notes de réunion et les fonctionnalités d'amélioration de la productivité.
Questions fréquemment posées
Quel est le TCAC attendu du marché de la reconnaissance de la parole et de la voix au cours de la période de prévision?
Quelle était la taille de l'industrie en 2024?
Quels sont les principaux facteurs qui stimulent le marché?
Quels sont les principaux acteurs du marché?
Quelle région devrait être la croissance la plus rapide sur le marché au cours de la période de prévision?
Quel segment devrait détenir la plus grande part du marché en 2032?
Auteur
Versha apporte plus de 15 ans d'expérience dans la gestion de missions de conseil dans des secteurs tels que l'alimentation et les boissons, les biens de consommation, les TIC, l'aérospatiale, etc. Son expertise transversale et son adaptabilité font d'elle une professionnelle polyvalente et fiable. Dotée de compétences analytiques pointues et d’un état d’esprit curieux, Versha excelle dans la transformation de données complexes en informations exploitables. Elle a fait ses preuves dans la compréhension de la dynamique du marché, l'identification des tendances et la fourniture de solutions sur mesure pour répondre aux besoins des clients. En tant que leader compétente, Versha a encadré avec succès des équipes de recherche et dirigé des projets avec précision, garantissant ainsi des résultats de haute qualité. Son approche collaborative et sa vision stratégique lui permettent de transformer les défis en opportunités et de produire constamment des résultats percutants. Qu'il s'agisse d'analyser les marchés, d'impliquer les parties prenantes ou d'élaborer des stratégies, Versha s'appuie sur sa profonde expertise et ses connaissances du secteur pour stimuler l'innovation et offrir une valeur mesurable.
Avec plus d'une décennie de leadership en recherche sur les marchés mondiaux, Ganapathy apporte un jugement aigu, une clarté stratégique et une expertise approfondie du secteur. Connu pour sa précision et son engagement inébranlable envers la qualité, il guide les équipes et les clients avec des insights qui génèrent constamment des résultats commerciaux impactants.


 Marché de la reconnaissance de la parole et de la voix
Marché de la reconnaissance de la parole et de la voix