Speech and Voice Recognition Market Size, Share, Growth & Industry Analysis, By Technology (Speech Recognition, Voice Recognition), By Deployment (Cloud-based, On-premises), By Vertical (Healthcare, IT & Telecommunications, Automotive, BFSI, Government & Legal, Education, Retail, Media & Entertainment, Others) and Regional Analysis, 2025-2032
Seiten: 170 | Basisjahr: 2024 | Veröffentlichung: July 2025 | Autor: Versha V. | Zuletzt aktualisiert: July 2025
Die Spracherkennung bezieht sich auf die technologische Fähigkeit, die gesprochene Sprache in einen schriftlichen Text umzuwandeln, während die Spracherkennung die Identifizierung von Individuen auf unterschiedlichen Stimmmerkmalen beinhaltet. Der Markt umfasst Hardware, Software und Dienste, die menschliche Sprache interpretieren und verarbeiten.
Zu den wichtigsten Anwendungen gehören virtuelle Assistenten, automatisierte Transkription, Sprachsysteme im Fahrzeug und die biometrische Authentifizierung. Diese Technologien werden in verschiedenen Branchen wie Gesundheitswesen, Finanzen, Einzelhandel und Unternehmen für die Befehlsausführung und die sichere Benutzerüberprüfung eingesetzt.
Übersicht über den Sprach- und Spracherkennungsmarkt
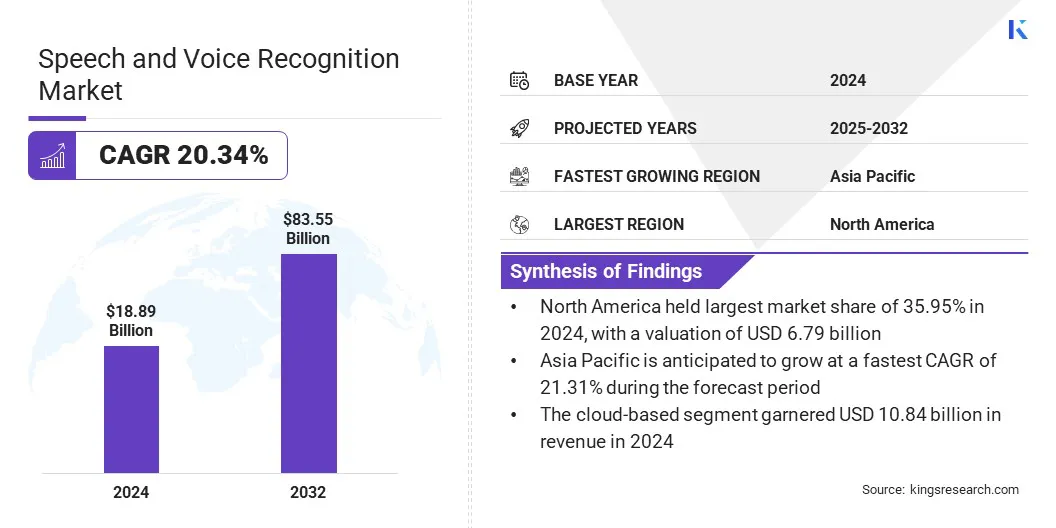
Die weltweite Marktgröße für Sprach- und Spracherkennung wurde im Jahr 2024 mit 18,89 Milliarden USD geschätzt und wird voraussichtlich von 22,65 Mrd. USD im Jahr 2025 auf 83,55 Mrd. USD bis 2032 wachsen, was im Prognosezeitraum eine CAGR von 20,34% aufwies.
Der Markt verzeichnet ein erhebliches Wachstum, was auf die steigende Integration von Sprachtechnologien in Bezug auf Unterhaltungselektronik, Automobilsysteme und Unternehmensanwendungen zurückzuführen ist. Die verstärkte Einführung intelligenter Assistenten, Fortschritte bei der Verarbeitung natürlicher Sprache und die wachsende Nachfrage nach kontaktlosen Schnittstellen tanken die Marktausdehnung.
Schlüsselhighlights
Die Größe der Sprach- und Spracherkennungsindustrie wurde im Jahr 2024 mit 18,89 Milliarden USD geschätzt.
Der Markt wird voraussichtlich von 2025 bis 2032 auf einer CAGR von 20,34% wachsen.
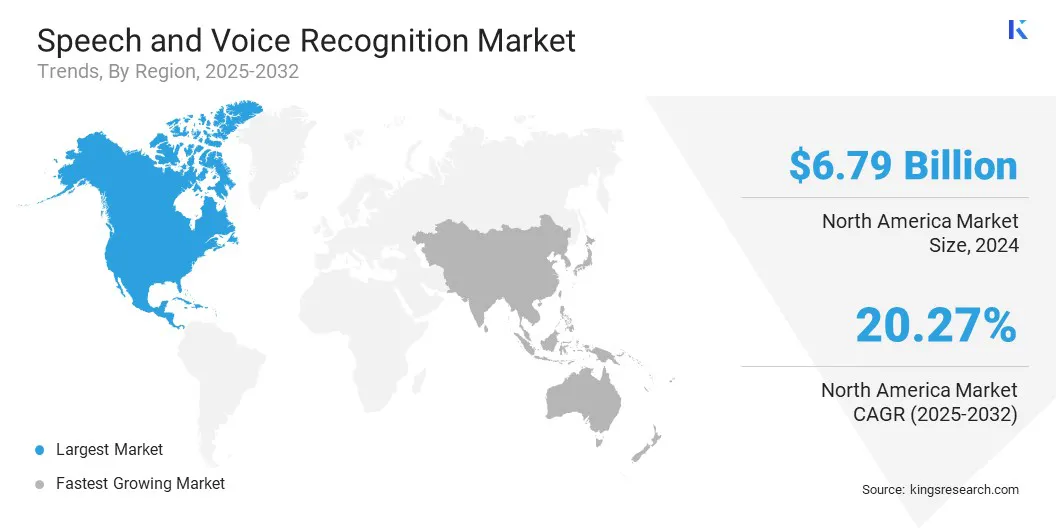
Nordamerika hatte im Jahr 2024 einen Anteil von 35,95% im Wert von 6,79 Milliarden USD.
Das Spracherkennungssegment erzielte 2024 einen Umsatz von 10,18 Milliarden USD.
Das Cloud-basierte Segment wird voraussichtlich bis 2032 46,23 Milliarden USD erreichen.
Das Gesundheitssegment wird voraussichtlich bis 2032 einen Umsatz von 14,11 Mrd. USD generieren.
Der asiatisch -pazifische Raum wird voraussichtlich im Prognosezeitraum auf einer CAGR von 21,31% wachsen.
Große Unternehmen, die in der Sprach- und Spracherkennung tätig sindIndustriesind Apple Inc., Amazon.com, Inc., Alphabet Inc., Microsoft, IBM, Baidu, Iflytek Corporation, Samsung, Meta, Soundhound Ai Inc., Sensory Inc., Realmatics, Verint Systems Inc., Cisco Systems, Inc. und OpenAI.
Sprachbasierte Lösungen verbessern die Benutzererfahrung, die betriebliche Effizienz und die Datensicherheit im Finanzsektor, indem sie natürliche, freihändige Interaktionen ermöglichen, die den Zugriff und die Transaktionen des Kontos vereinfachen. Sie automatisieren Routineaufgaben, verringern die Abhängigkeit von menschlichen Agenten und senken die Servicekosten. Darüber hinaus bietet die Spracherkennung eine biometrische Authentifizierung, um sicheren Zugriff auf vertrauliche Informationen zu gewährleisten und das Vertrauen in das digitale Bankgeschäft zu verstärken.
Zum Beispiel hat Omniwire, Inc. im April 2025 mit Nowutalkai, Inc. zusammengearbeitet, um den ersten AI Voice Personal Banker mit der "Voice to Action" -Technologie von Nowutalkai zu starten. Der mehrsprachige, konversende Assistent wird als Weißmarkierungslösung für Banken, Fintechs und Kreditgenossenschaften angeboten, die sich ein sicheres, sprachliches Bankgeschäft über die Cloud-basierte Banken-AS-A-Dienst-Plattform von Omniwire ermöglichen.
Diese Entwicklung zeigt die Integration fortschrittlicher Sprachtechnologien in Kernbankenplattformen, die sich mit der Nachfrage nach sicheren, effizienten und benutzerfreundlichen Finanzdienstleistungen befassen und damit das Wachstum des Marktes vorantreiben.
Marktfahrer
Steigende Einführung von virtuellen Assistenten von KI-betriebenen
Der Fortschritt des globalen Marktes für Sprach- und Spracherkennung wird hauptsächlich durch die zunehmende Integration von virtuellen Assistenten von KI-betriebenen Virtuellen in Unterhaltungselektronik und intelligente Geräte angeheizt.
Als Unternehmen und Haushalte nehmen anSmart Lautsprecher, Smartphones und Infotainmentsysteme im Auto, steigt die Nachfrage nach genauen und reaktionsschnellen Sprachschnittstellen. Diese AI-fähigen Systeme verbessern die Benutzererfahrung, indem sie Freisprechvorgänge, effizientes Informationsabruf und Echtzeit-Aufgabenausführung, Förderung der Bequemlichkeit und Zugänglichkeit ermöglichen.
Durch die Integration der Algorithmen für erweiterte natürliche Sprache (NLP) und maschinelles Lernen können diese Systeme kontextbezogene Sprache, Akzente und Benutzerbefehle mit hoher Genauigkeit verstehen. Darüber hinaus konzentrieren sich Unternehmen darauf, personalisiertere und kontextbewusster Sprachschnittstellen aufzubauen, die mit den sich entwickelnden Benutzererwartungen übereinstimmen. Diese zunehmende Abhängigkeit von sprachbasierten Technologien trägt erheblich zur Markterweiterung bei.
Im Februar 2025 startete Amazon Alexa+, einen generativen Assistent für KI, der für natürliche, intelligente Sprachinteraktionen entwickelt wurde. Alexa+ integriert in Advanced LLMs und verbessert die Aufgabenautomatisierung, die Smart -Home -Steuerung und die personalisierte Unterstützung auf allen Geräten. Dieses Upgrade zielt darauf ab, nahtlose Echtzeit-Konversationserfahrungen zu liefern.
Marktherausforderung
Akzent- und Kontextbeschränkungen bei der Spracherkennung
Eine große Herausforderung, die die Entwicklung des Marktes für Sprach- und Spracherkennung behindert, ist die genaue Interpretation verschiedener Akzente, Dialekte und kontextabhängiger Sprachgebrauch. Dies führt häufig zu einer verringerten Genauigkeit, insbesondere in mehrsprachigen Umgebungen oder Umgebungen mit hohen Rauschpegeln, die die Benutzererfahrung und die Systemzuverlässigkeit beeinflussen.
Um diese Herausforderung zu befriedigen, entwickeln Unternehmen Modelle (Advanced Natural Language Processing), die Deep -Lern -Techniken enthalten und nach umfangreichen, sprachlich unterschiedlichen Datensätzen geschult werden. Diese Modelle sollen die Fähigkeit des Systems verbessern, nuancierte Sprachvariationen zu erkennen und die Benutzerabsicht effektiver zu verstehen.
Darüber hinaus ermöglichen Verbesserungen des Kontextbewusstseins die Systeme, die Konversationshinweise besser zu interpretieren und eine breitere Zugänglichkeit und die reale Leistung zu unterstützen.
Im März 2025 führte OpenAI eine neue Suite von Audiomodellen der nächsten Generation durch ihre API ein, die hochmoderne Sprach- und Text-zu-Sprach-Funktionen enthielt. Die Veröffentlichung wurde für eine hohe Genauigkeit und Zuverlässigkeit bei herausfordernden akustischen Bedingungen entwickelt und unterstützt die Entwicklung anpassbarer und intelligenter Sprachagenten in verschiedenen Anwendungen.
Markttrend
Integration der Spracherkennung in die Gesundheitsbranche
Der globale Markt für Sprach- und Spracherkennung wird durch die Integration von Sprach -KI -Technologien in Gesundheitssysteme beeinflusst. Dieser Trend steigert die Einführung fortschrittlicher sprachfähiger Tools, die klinische Workflows optimieren, die administrativen Belastungen reduzieren und das Engagement der Patienten verbessern.
Integration von Spracherkennungsfähigkeiten inelektronische Gesundheitsakte (EHR)Plattformen und klinische Dokumentationsprozesse verbessert die Genauigkeit, beschleunigt die Dateneingabe und steigert die Produktivität der Kliniker.
Die Fähigkeit dieser Systeme, natürliche Sprache zu interpretieren, mehrsprachige Kommunikation zu unterstützen und sich wiederholende Aufgaben zu automatisieren, verbessert die betriebliche Effizienz und die Pflegequalität erheblich. Darüber hinaus fördert die wachsende Nachfrage nach Umgebungs- und Freisprechlösungen im Gesundheitswesen die anhaltende Investitionen in sprachfähige Gesundheitsanwendungen, die Sprach- und Spracherkennung als kritische Komponente für die digitale Transformation globaler Gesundheitsdienste positionieren.
Im März 2025 stellte Microsoft Corp. Dragon Copilot vor, einen mit KI betriebenen Sprachassistenten für klinische Workflows. Die Lösung integriert Dragon Medical One und DAX Copilot, um die Dokumentation zu optimieren, die Verwaltungsaufgaben zu automatisieren und die Effizienz der Kliniker zu verbessern. Dragon Copilot basiert auf Microsoft Cloud für das Gesundheitswesen und kombiniert Umgebungshörungen, natürliche Sprachverarbeitung und generative KI, um sowohl das Wohlbefinden der Anbieter als auch die Patientenergebnisse zu verbessern.
Marktbericht für Sprach- und Spracherkennung Snapshot
Segmentierung
Details
Nach Technologie
Spracherkennung, Spracherkennung
Durch Bereitstellung
Cloud-basierte, lokale
Von vertikal
Gesundheitswesen, IT & Telecommunications, Automotive, BFSI, Regierung und Recht, Bildung, Einzelhandel, Medien und Unterhaltung, andere
Nach Region
Nordamerika: USA, Kanada, Mexiko
Europa: Frankreich, Großbritannien, Spanien, Deutschland, Italien, Russland, Rest Europas
Nach Technologie (Spracherkennung und Spracherkennung): Das Segment zur Spracherkennung verdiente sich im Jahr 2024 in Höhe von 10,18 Milliarden USD aufgrund seiner weit verbreiteten Akzeptanz in virtuellen Assistenten, Transkriptionsdiensten und Kundendienstautomatisierung in allen Branchen.
Durch Bereitstellung (Cloud-basierte und lokale): Das Cloud-basierte Segment hielt einen Anteil von 57,37%im Jahr 2024, das durch seine Skalierbarkeit, einfache Integration und niedrigere Kosten für die Vorabfront-Infrastruktur angetrieben wurde.
Von Vertical (Healthcare, IT & Telecommunications, Automotive, BFSI, Government & Legal, Education, Retail, Media & Entertainment und andere): Das Gesundheitssegment wird aufgrund der zunehmenden Verwendung von Sprachdokumentationen und Sprachbekämpfungsdokumentationen und Sprachbehörden von Patienten Engagement-Tools mit sprachfähigen Dokumentationen und sprachgesteuerten Patienten mit Sprachbehörden prognostiziert.
Regionalanalyse für Sprach- und Spracherkennung
Basierend auf der Region wurde der Markt in Nordamerika, Europa, Asien -Pazifik, Naher Osten und Afrika und Südamerika eingeteilt.
Der Markt für Sprach- und Spracherkennung in Nordamerika machte im Jahr 2024 einen erheblichen Anteil von 35,95% im Wert von 6,79 Milliarden USD aus. Diese Dominanz wird durch starke Investitionen in künstliche Intelligenz und Technologien für natürliche Sprachverarbeitung verstärkt, die die Fähigkeiten von sprachfähigen Systemen erheblich vorangetrieben haben.
Diese Innovationen werden zunehmend in Unterhaltungselektronik, Unternehmenssoftware und digitale Dienste integriert und fördern nahtlose, freihändige Benutzererlebnisse. Die Verfügbarkeit einer hohen digitalen Infrastruktur, qualifizierten Talente und der Einführung der frühen Technologie beschleunigt diesen Trend weiter.
Nordamerikanische Unternehmen und Verbraucher werden als primäre Schnittstelle für Geräte- und Anwendungsinteraktion aufgeteilt, und nehmen die Tools für Sprach- und Spracherkennung an, was die führende Position der Region festigt.
Im Januar 2025 sammelten ElevenLabs 180 Millionen USD in der Serie -C -Finanzierung, um seine KI -Audio -Technologie voranzutreiben, seine Forschung zu erweitern und neue Produkte zu entwickeln, die Sprach- und Klang für digitale Interaktionen von zentraler Bedeutung machen.
Die asiatisch-pazifische Sprache und SpracherkennungIndustrieEs wird erwartet, dass sie im Prognosezeitraum die schnellste CAGR von 21,31% registrieren. Dieses Wachstum wird hauptsächlich durch die wachsende Smartphone -Penetration und die Integration von Sprachassistenten in mobile Geräte gefördert.
Mit einer großen und wachsenden Bevölkerung von Mobilfunknutzern, insbesondere in Ländern wie China, Indien und südostasiatischer Nationen, besteht eine starke Nachfrage nach intuitiver und lokalisierter Sprachinteraktion. Hersteller und Dienstleister integrieren Spracherkennungsfunktionen, um die Zugänglichkeit, die Benutzerfreundlichkeit und die Personalisierung in Muttersprachen und Dialekten zu verbessern.
Dieser mobil-zentrierte Sprachschnittstellen-Trend verändert das digitale Engagement in Bereichen wie E-Commerce, Banking, Gesundheitswesen und Bildung. Der Aufstieg erschwinglicher Smartphones mit eingebetteten KI -Fähigkeiten fördert dieses Wachstum weiter.
Im Dezember 2023 haben das Institut für Infocomm Research von A*Star, IMDA und AI Singapore eine Partnerschaft eingereicht, um das erste regionale Großsprachmodell in Südostasien im National Multimodal LLM -Programm in Singapur zu starten. Die Initiative zielt darauf ab, kulturell kontextbezogene Sprach -Text -Modelle zu entwickeln, die auf südostasiatische Sprachen zugeschnitten sind und die Funktionen der lokalen Sprachinteraktion verbessern.
Regulatorische Rahmenbedingungen
In den USA, Die Federal Trade Commission (FTC) und die Federal Communications Commission (FCC) regulieren Sprachtechnologien unter Verbraucherschutz und Kommunikationsgesetzen, wobei der Schwerpunkt auf Datenschutz, Überwachung und faire Geschäftspraktiken liegt.
In EuropaDie allgemeine Datenschutzverordnung (DSGVO) regelt die Sammlung, Verarbeitung und Speicherung von Sprachdaten, bei denen Unternehmen bei der Bereitstellung von Spracherkennungstechnologien die Transparenz, die Einwilligung und die Datenminimierung der Benutzer und die Datenminimierung sicherstellen müssen.
In ChinaDie Cyberspace Administration of China (CAC) erzwingt das Gesetz zur Schutz des persönlichen Informationen (PIPL), das strenge Anforderungen für biometrische Daten wie Sprach, die Sicherstellung der lokalen Datenspeicherung und die Einwilligung des Benutzers enthält.
In JapanDie Personal Information Protection Commission (PPC) überwacht das Gesetz zum Schutz der persönlichen Informationen (APPI), die die Verwendung von Sprachdaten reguliert, insbesondere in Anwendungen, die eine biometrische Authentifizierung oder Sprachprofilierung betreffen.
Wettbewerbslandschaft
Die globale Sprach- und SpracherkennungIndustriewird durch schnelle technologische Innovation gekennzeichnet, unterstützt durch die zunehmende Integration von Sprachschnittstellen in alltägliche Geräte und Unternehmenslösungen.
Unternehmen arbeiten aktiv mit KI-Forschungsinstitutionen und Cloud-Dienstanbietern zusammen, um fortschrittliche Sprachanwendungen mitzuentwickeln, um schnellere, genauere und kontextbezogene Sprachverarbeitung zu liefern. Diese Kooperationen ermöglichen es Unternehmen, Sprachanalysefunktionen zu verbessern und die Reaktionsfähigkeit der Systeme in verschiedenen Umgebungen wie Call Centers, Automobiles und intelligenten Geräten zu verbessern.
Unternehmen starten weiterhin speziell gebaute Spracherkennungsplattformen, die leicht in Unternehmens-Workflows eingebettet werden können und die Skalierbarkeit und mehrsprachige Anpassungsfähigkeit bieten. Diese kontinuierliche Verschiebung in Richtung Integration, Anpassbarkeit und Leistungsoptimierung verstärkt den Wettbewerb. Die Spieler bemühen sich, sich durch proprietäre Modelle und regionspezifische Sprachlösungen zu unterscheiden, die auf die Benutzerbedürfnisse zugeschnitten sind.
Im März 2025 arbeitete Kyndryl mit Microsoft zusammen, um Dragon Copilot, einen mit AI betriebenen Gesundheitsassistenten, zu starten, der generative KI für das Hör- und Spracherkennung von Ambient nutzte. Die Partnerschaft zielt darauf ab, die klinische Dokumentation zu automatisieren, die Effizienz der Kliniker zu verbessern und die Patientenversorgung zu verbessern, indem Sprachdiktationen und natürliche Sprachfunktionen in Gesundheitswesen integriert werden.
Im September 2024 startete Deepgram seine Voice Agent-API, eine einheitliche Sprach-zu-Voice-Lösung, die es in Echtzeit-, natürlichen Gesprächen zwischen Menschen und Maschinen ermöglichte. Die API integriert die erweiterte Spracherkennung und Sprachsynthese, um Unternehmen und Entwicklern dabei zu helfen, intelligente Sprachbots und KI -Agenten für Anwendungen wie Kundensupport und Bestellverarbeitung aufzubauen.
Schlüsselunternehmen im Markt für Sprach- und Spracherkennung:
Im April 2025Aiola führte Jargonic ein, ein Fundament-ASR-Modell, das für eine domänenspezifische Transkription in Echtzeit unter Verwendung von Schlüsselwort-Spotten und Null-Shot-Lernen entwickelt wurde. Jargonic bietet eine überlegene Leistung in lauten industriellen Umgebungen, behandelt die mehrsprachige Spracherkennung und übertrifft die Wettbewerber in der Wortfehlerrate und des Jargon -Term -Rückrufs, ohne dass die Umschulung für neue Branchenvokabulare erforderlich ist.
Im April 2025, Kia erweiterte sein generatives KI-Anerkennungssystem KI AS-Assistent über Over-the-Air-Updates auf den europäischen Markt. Das System, das zunächst in Korea und den USA eingeführt wurde, ermöglicht die natürliche Interaktion und eine verbesserte Fahrzeugkontrolle. Er wird für EV3-Modelle und andere CCNC-Modelle verfügbar sein.
Im April 2025, Intelepeer startete Advanced Voice AI-Funktionen mit automatischer Spracherkennung (ASR) und Text-to-Speech (TTS) Streaming. Die Technologie entwickelt intern und ermöglicht Echtzeitgespräche, verbessert das Kundenerlebnis durch natürliche Interaktionen und geringe Latenz und stärkt die End-to-End-KI-Plattform des Unternehmens mit verbesserten Analysen, Spracherkennung und anpassbaren Automatisierungseinstellungen.
Im Juni 2024, Philips Sprache von Sprachverarbeitungslösungen arbeitete mit Sembly AI zusammen, um drei neue Audio -Rekorder zu starten, die in die KI -Technologie integriert wurden. Die Geräte bieten automatische Transkriptionen, Zusammenfassungen, Aktionslisten und Erkenntnisse, während Sembly AI Sprechertrennung, Meeting-Notizen und Produktivitätsfunktionen hinzufügt.
Häufig gestellte Fragen
Was ist der erwartete CAGR für den Markt für Sprach- und Spracherkennung im Prognosezeitraum?
Wie groß war die Branche im Jahr 2024?
Was sind die wichtigsten Faktoren, die den Markt vorantreiben?
Wer sind die wichtigsten Marktteilnehmer?
Welche Region wird voraussichtlich im Prognosezeitraum am schnellsten wachsen?
Welches Segment wird voraussichtlich 2032 den größten Marktanteil haben?
Autor
Versha verfügt über mehr als 15 Jahre Erfahrung in der Leitung von Beratungsaufträgen in verschiedenen Branchen, darunter Lebensmittel und Getränke, Konsumgüter, IKT, Luft- und Raumfahrt und mehr. Ihr bereichsübergreifendes Fachwissen und ihre Anpassungsfähigkeit machen sie zu einer vielseitigen und zuverlässigen Fachkraft. Mit scharfen analytischen Fähigkeiten und einer neugierigen Denkweise ist Versha hervorragend darin, komplexe Daten in umsetzbare Erkenntnisse umzuwandeln. Sie verfügt über eine nachgewiesene Erfolgsbilanz darin, Marktdynamiken zu entschlüsseln, Trends zu erkennen und maßgeschneiderte Lösungen für die Erfüllung der Kundenbedürfnisse bereitzustellen. Als erfahrene Führungskraft hat Versha Forschungsteams erfolgreich betreut und Projekte präzise geleitet, um qualitativ hochwertige Ergebnisse sicherzustellen. Ihr kollaborativer Ansatz und ihre strategische Vision ermöglichen es ihr, Herausforderungen in Chancen zu verwandeln und stets wirkungsvolle Ergebnisse zu liefern. Ob es darum geht, Märkte zu analysieren, Stakeholder einzubeziehen oder Strategien zu entwickeln – Versha greift auf ihr umfassendes Fachwissen und ihre Branchenkenntnisse zurück, um Innovationen voranzutreiben und messbaren Wert zu liefern.
Mit über einem Jahrzehnt Forschungserfahrung in globalen Märkten bringt Ganapathy scharfsinniges Urteilsvermögen, strategische Klarheit und tiefes Branchenwissen mit. Bekannt für Präzision und unerschütterliches Engagement für Qualität, führt er Teams und Kunden mit Erkenntnissen, die konsequent zu wirkungsvollen Geschäftsergebnissen führen.


 Sprach- und Spracherkennungsmarkt
Sprach- und Spracherkennungsmarkt