Размер рынка распознавания и голоса, доля, анализ роста и промышленности, технологии (распознавание речи, распознавание голоса), развертывание (облачные, локальные), по вертикали (здравоохранение, IT и телекоммуникации, автомобиль, BFSI, правительство и юридическое, образование, розничная торговля, медиа и развлечения, другие) и региональный анализ,, анализ, анализ, анализ, анализ, анализ, региональный анализ, анализ, правительство и юридическое образование, образование, розничная торговля, медиа и развлечения, другие) и региональный анализ,, анализ, BFSI, правительство и юридические, образовательные, розничные средства, медиа и развлечения, другие) и региональный анализ. 2025-2032
Страницы: 170 | Базовый год: 2024 | Релиз: July 2025 | Автор: Versha V. | Последнее обновление: July 2025
Распознавание речи относится к технологическому потенциалу преобразовать разговорную формулировку в письменный текст, в то время как распознавание голоса включает в себя идентификацию людей на основе различных вокальных характеристик. Рынок охватывает аппаратное, программное обеспечение и услуги, которые интерпретируют и обрабатывают человеческую речь.
Ключевые приложения включают виртуальные помощники, автоматическую транскрипцию, голосовые системы в транспортных средствах и биометрическую аутентификацию. Эти технологии используются в различных отраслях, таких как здравоохранение, финансы, розничная торговля и предприятие для выполнения команд и защищенную проверку пользователей.
Обзор рынка распознавания речи и голоса
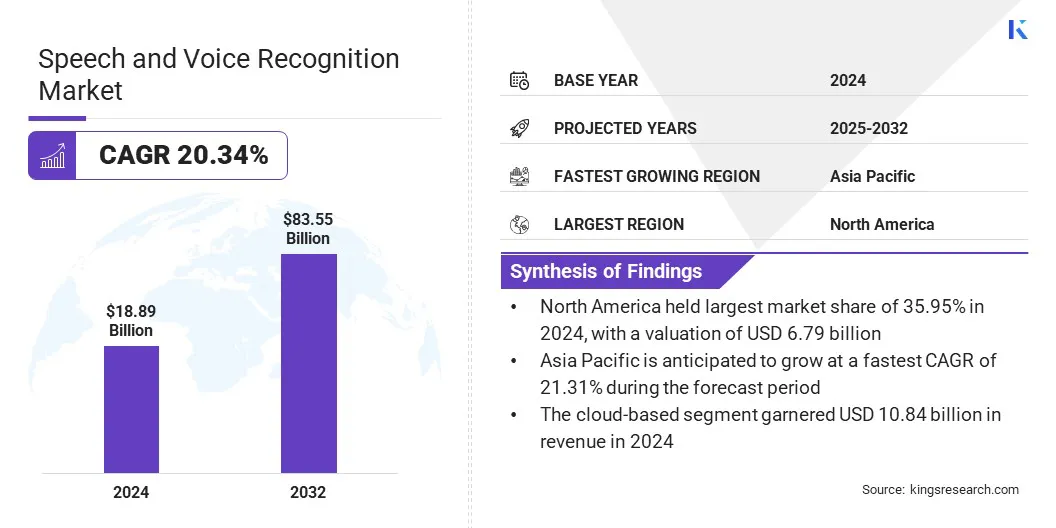
В 2024 году размер рынка глобального распознавания речи и голоса был оценен в 18,89 млрд долларов США в 2024 году и, по прогнозам, расти с 22,65 млрд долларов в 2025 году до 83,55 млрд долларов США к 2032 году, демонстрируя CAGR 20,34% в течение прогнозируемого периода.
Рынок переживает значительный рост, обусловленное растущей интеграцией технологий с поддержкой голоса по потребительской электронике, автомобильных системам и корпоративным приложениям. Повышение принятия умных помощников, достижения в области обработки естественного языка и растущий спрос на бесконтактные интерфейсы подпитывают расширение рынка.
Ключевые основные моменты
Размер индустрии распознавания речи и голоса был оценен в 18,89 млрд долларов США в 2024 году.
Предполагается, что рынок вырастет в среднем на 20,34% с 2025 по 2032 год.
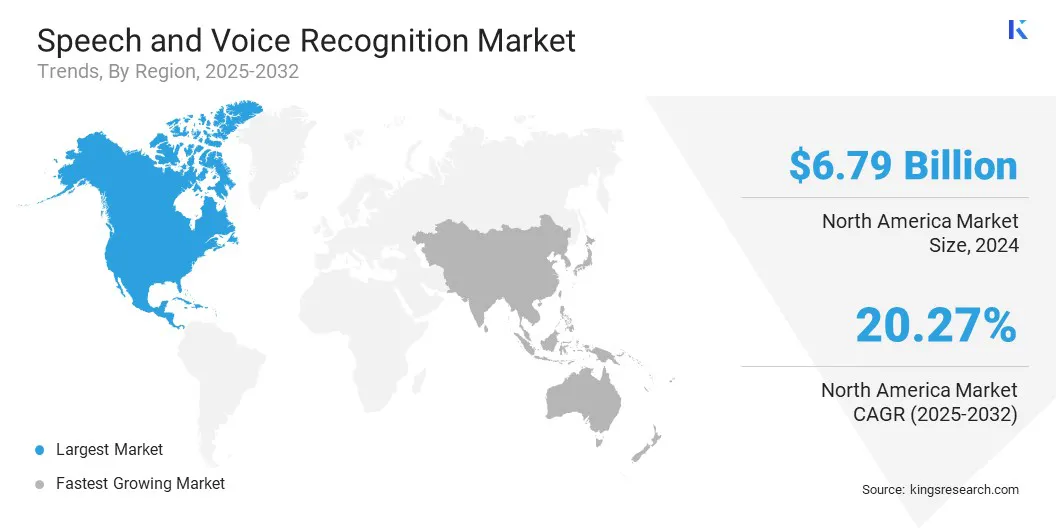
В 2024 году Северная Америка в размере 35,95% стоила 6,79 миллиарда долларов США.
Сегмент признания речи получил 10,18 млрд долларов дохода в 2024 году.
Ожидается, что облачный сегмент достигнет 46,23 млрд долларов к 2032 году.
Предполагается, что сегмент здравоохранения принесет доход в размере 14,11 млрд долларов США к 2032 году.
Ожидается, что в Азиатско -Тихоокеанском регионе вырастет на 21,31% в течение прогнозируемого периода.
Основные компании, работающие в рамках распознавания речи и голосапромышленностьApple Inc., Amazon.com, Inc., Alphabet Inc., Microsoft, IBM, Baidu, Iflytek Corporation, Samsung, Meta, Soundhound Ai Inc., Sensory Inc., Speechmatics, Verint Systems Inc, Cisco Systems, Inc. и Openai.
Голосовые решения улучшают пользовательский опыт, эффективность работы и безопасность данных в финансовом секторе, позволяя естественным, беспрепятственному взаимодействию, которые упрощают доступ к учетной записи и транзакции. Они автоматизируют рутинные задачи, снижая зависимость от человеческих агентов и снижают расходы на обслуживание. Кроме того, распознавание голоса обеспечивает биометрическую аутентификацию, обеспечивая безопасный доступ к конфиденциальной информации и усиление доверия к цифровому банкингу.
Например, в апреле 2025 года Omniwire, Inc. сотрудничала с Nowutalkai, Inc., чтобы запустить первого персонального банкира AI Voice, используя технологию Nowutalkai «Голос к действию». Многоязычный, разговорной помощник предлагается в качестве решения белой марки для банков, финтех и кредитных союзов, обеспечивая безопасное, голосовое банковское дело через облачное банковское дело Omniwire.
Эта разработка демонстрирует интеграцию передовых голосовых технологий в основные банковские платформы, решает спрос на безопасные, эффективные и удобные финансовые услуги, тем самым способствуя росту рынка.
Рыночный драйвер
Растущее внедрение виртуальных помощников на основе ИИ
Прогресс мирового рынка распознавания речи и голоса в первую очередь подпитывается растущей интеграцией виртуальных помощников на основе AI в потребительскую электронику и интеллектуальные устройства.
Как присыпают предприятия и домохозяйстваумные динамики, Смартфоны и информационно-развлекательные системы в автомобилях, спрос на точные и отзывчивые голосовые интерфейсы растет. Эти системы с поддержкой AI усиливают пользовательский опыт, позволяя операциям без помощи рук, эффективным поиском информации и выполнению задач в реальном времени, содействии удобству и доступности.
Интеграция передовой обработки естественного языка (NLP) и алгоритмов машинного обучения позволяет этим системам понимать контекстную речь, акценты и команды пользователей с высокой точностью. Кроме того, компании сосредоточены на создании более персонализированных и контекстных голосовых интерфейсов, которые соответствуют развивающимся ожиданиям пользователей. Эта растущая зависимость от голосовых технологий значительно способствует расширению рынка.
В феврале 2025 года Amazon запустила Alexa+, генеративного помощника по AI, предназначенному для естественных, интеллектуальных голосовых взаимодействий. Интегрированные с Advanced LLMS, Alexa+ улучшает автоматизацию задач, управление умным домом и персонализированную помощь на всех устройствах. Это обновление направлено на предоставление бесшовных, в реальном времени разговорных опытов.
Рыночный вызов
Акцентные и контекстуальные ограничения в распознавании речи
Основной проблемой, препятствующей развитию рынка речи и голоса, является точная интерпретация различных акцентов, диалектов и контекста-зависимого от языка. Это часто приводит к снижению точности, особенно в многоязычных настройках или средах с высоким уровнем окружающего шума, что влияет на пользовательский опыт и надежность системы.
Чтобы решить эту проблему, компании разрабатывают современные модели обработки естественного языка (NLP), которые включают методы глубокого обучения и обучены обширным лингвистически разнообразным наборам данных. Эти модели предназначены для улучшения способности системы распознавать тонкие вариации речи и более эффективно понимать намерения пользователя.
Кроме того, улучшения в контекстном осознании позволяют системам лучше интерпретировать разговорные сигналы, поддерживая более широкую доступность и реальную производительность.
В марте 2025 года Openai представила новый набор аудио-моделей следующего поколения через свой API с самыми современными возможностями речи в тексте и текста в речь. Предназначенный для высокой точности и надежности в сложных акустических условиях, релиз поддерживает разработку настраиваемых и интеллектуальных голосовых агентов в разных приложениях.
Тенденция рынка
Интеграция признания речи в индустрии здравоохранения
На мировом рынке речи и голоса влияет интеграция технологий Voice AI в системах здравоохранения. Эта тенденция повышает принятие передовых инструментов с поддержкой голоса, которые оптимизируют клинические рабочие процессы, снижают административное бремя и повышают вовлечение пациентов.
Интеграция возможностей распознавания речи вЭлектронная медицинская запись (EHR)Платформы и процессы клинической документации повышают точность, ускоряют ввод данных и повышают производительность врача.
Способность этих систем интерпретировать естественный язык, поддержать многоязычное общение и автоматизировать повторяющиеся задачи значительно повышает эффективность работы и качество ухода. Кроме того, растущий спрос на решения для окружающей среды и громкой связи в условиях здравоохранения способствует дальнейшему инвестициям в приложения для здравоохранения с поддержкой голоса, позиционируя речи и распознавание речи и голоса в качестве критического компонента в цифровой трансформации глобальных медицинских услуг.
В марте 2025 года Microsoft Corp. представила Dragon Copilot, голосового помощника по AI для клинических рабочих процессов. Решение объединяет Dragon Medical One и Dax Copilot для оптимизации документации, автоматизации административных задач и повышения эффективности врача. Dragon Copilot, построенный на Microsoft Cloud для здравоохранения, сочетает в себе слушание окружающей среды, обработку естественного языка и генеративный ИИ для улучшения как благополучия поставщиков, так и результатов пациента.
Снимок рынка распознавания речи и голоса
Сегментация
Подробности
По технологиям
Распознавание речи, распознавание голоса
Путем развертывания
Облачный, локальный
Вертикальным
Здравоохранение, IT & Telecommunitions, Automotive, BFSI, правительство и юридическое образование, образование, розничная торговля, средства массовой информации и развлечения, другие
По региону
Северная Америка: США, Канада, Мексика
Европа: Франция, Великобритания, Испания, Германия, Италия, Россия, остальная часть Европы
Азиатско-Тихоокеанский регион: Китай, Япония, Индия, Австралия, АСЕАН, Южная Корея, остальная часть Азиатско-Тихоокеанского региона
Ближний Восток и Африка: Турция, США, Саудовская Аравия, Южная Африка, остальная часть Ближнего Востока и Африки
Южная Америка: Бразилия, Аргентина, остальная часть Южной Америки
Сегментация рынка
По технологиям (распознавание речи и распознавание голоса): сегмент распознавания речи заработал 10,18 млрд долларов США в 2024 году из -за его широкого распространения в виртуальных помощниках, услугах транскрипции и автоматизации обслуживания клиентов в разных отраслях.
Развертывание (облачное и локальное): облачный сегмент в 2024 году удерживал долю 57,37%, подкрепляется его масштабируемостью, простотой интеграции и более низкими затратами на инфраструктуру авансов.
По вертикали (здравоохранение, ИТ и телекоммуникации, автомобильная, BFSI, правительство и юридические, образование, розничная торговля, медиа и развлечения и другие): сегмент здравоохранения, по прогнозам, будет достигнут 14,11 млрд. Долл. США к 2032 году из-за растущего использования клинической документации с поддержкой речи и инструментов привлечения пациентов.
Региональный анализ рынка распознавания речи и голоса
Основываясь на регионе, рынок был классифицирован в Северной Америке, Европе, Азиатско -Тихоокеанском регионе, Ближнем Востоке и Африке и Южной Америке.
Рынок речи и голоса в Северной Америке составлял значительную долю 35,95% в 2024 году стоимостью 6,79 миллиарда долларов США. Это доминирование усиливается сильными инвестициями в технологии искусственного интеллекта и обработки естественного языка, которые значительно продвинули возможности систем с поддержкой голоса.
Эти инновации все чаще интегрируются в потребительскую электронику, корпоративное программное обеспечение и цифровые услуги, способствуя бесшовным, без предоставления пользовательским опытом. Доступность высокой цифровой инфраструктуры, квалифицированных талантов и раннего внедрения технологий еще больше ускоряет эту тенденцию.
С голосом, становящимся основным интерфейсом для взаимодействия с устройствами и приложениями, североамериканские предприятия и потребители принимают инструменты распознавания речи и голоса, укрепляя главную позицию региона.
В январе 2025 года ElevenLabs собрал 180 миллионов долларов США в области финансирования серий C для продвижения своей технологии AI Audio, расширения своих исследований и разработки новых продуктов, которые делают голос и звук центральным для цифровых взаимодействий.
Азиатско-тихоокеанское распознавание речи и голосапромышленностьОжидается, что зарегистрирует самый быстрый CAGR 21,31% в течение прогнозируемого периода. Этот рост в первую очередь способствует расширяющемуся проникновению смартфонов и интеграцией голосовых помощников в мобильных устройствах.
С большим и растущим населением пользователей-мобильных людей, особенно в таких странах, как Китай, Индия и страны Юго-Восточной Азии, существует высокий спрос на интуитивное и локальное голосовое взаимодействие. Производители и поставщики услуг интегрируют функции распознавания голоса для повышения доступности, удобства пользователя и персонализации на местных языках и диалектах.
Эта мобильная тенденция голосового интерфейса преобразует цифровое взаимодействие в таких секторах, как электронная коммерция, банковская деятельность, здравоохранение и образование. Рост доступных смартфонов со встроенными возможностями ИИ еще больше стимулирует этот рост.
В декабре 2023 года институт исследований Infocomm, IMDA и AI Сингапура, заключили партнерские отношения для запуска первой региональной крупной языковой модели Юго -Восточной Азии в рамках программы национальной мультимодальной LLM в Сингапуре. Эта инициатива направлена на развитие культурно контекстуальных речевых моделей, адаптированных к языкам Юго -Восточной Азии, усиливая возможности локального голосового взаимодействия.
Нормативные рамки
В СШАФедеральная торговая комиссия (FTC) и Федеральная комиссия по связи (FCC) регулируют голосовые технологии в соответствии с законами о защите потребителей и коммуникациях, сосредоточив внимание на конфиденциальности, наблюдении и справедливой деловой практике.
В Европе, Общее регулирование защиты данных (GDPR) регулирует сбор, обработку и хранение голосовых данных, требуя от компаний обеспечить прозрачность, согласие пользователя и минимизацию данных при развертывании технологий распознавания голоса.
В Китае, Администрация киберпространства Китая (CAC) обеспечивает соблюдение закона о защите личной информации (PIPL), который включает в себя строгие требования к биометрическим данным, таким как голос, обеспечение локального хранения данных и согласия пользователя.
В Японии, Комиссия по защите личной информации (PPC) контролирует закон о защите личной информации (APPI), который регулирует использование голосовых данных, особенно в приложениях, включающих биометрическую аутентификацию или профилирование голоса.
Конкурентная ландшафт
Глобальное распознавание речи и голосапромышленностьхарактеризуется быстрыми технологическими инновациями, поддерживаемой растущей интеграцией голосовых интерфейсов в повседневные устройства и корпоративные решения.
Компании активно сотрудничают с научно-исследовательскими институтами ИИ и поставщиками облачных услуг для совместной разработки приложений с поддержкой голоса, стремясь обеспечить более быструю, более точную обработку речи. Это сотрудничество позволяет фирмам расширять возможности голосовой аналитики и улучшать реагирование системы в различных средах, таких как центры вызовов, автомобили и интеллектуальные устройства.
Компании дополнительно запускают специально построенные платформы распознавания голоса, которые могут быть легко встроены в корпоративные рабочие процессы, предлагая масштабируемость и многоязычную адаптивность. Этот постоянный сдвиг в направлении интеграции, настраиваемости и оптимизации производительности усиливает конкуренцию, и игроки стремятся дифференцировать себя через проприетарные модели и специфичные для региона голосовые решения, адаптированные к потребностям пользователей.
В марте 2025 года Kyndryl сотрудничал с Microsoft для запуска Dragon Copilot, ассистента здравоохранения с AI, использующим генеративное ИИ для прослушивания окружающей среды и распознавания голоса. Партнерство направлено на автоматизацию клинической документации, повышение эффективности клиницистов и улучшение ухода за пациентами за счет интеграции возможностей голосового и естественного языка в рабочие процессы здравоохранения.
В сентябре 2024 года Deepgram запустила свой API голосового агента, объединенное решение голоса к Voice, позволяющее в реальном времени, естественные разговоры между людьми и машинами. API объединяет расширенное распознавание речи и синтез голоса, чтобы помочь предприятиям и разработчикам создавать интеллектуальные голосовые череды и агенты искусственного интеллекта для таких приложений, как поддержка клиентов и обработка заказов.
Ключевые компании на рынке распознавания речи и голоса:
Последние разработки (запуск продукта/совместная работа)
В апреле 2025 года, AIOLA представила Jargonic, модель Foundation ASR, предназначенную для транскрипции в реальном времени, специфичной для доменов с использованием определения ключевых слов и нулевого обучения. Jargonic предлагает превосходную производительность в шумных промышленных настройках, обрабатывает многоязычное распознавание речи и превосходит конкурентов по частоте ошибок в словах и отзыве с термином жаргона, не требуя переподготовки для новой отрасли.
В апреле 2025 годаKia расширила свою генеративную систему распознавания голоса с AI, помощником по искусственному интеллекту, на европейский рынок посредством обновлений в эфире. Первоначально представленная в Корее и Соединенных Штатах, система обеспечивает естественное взаимодействие и усиление управления транспортными средствами и будет доступна на моделях EV3 и других моделях, оснащенных CCNC.
В апреле 2025 года, Intelepeer запустила возможности Advanced Voice AI с использованием автоматического распознавания речи (ASR) и потоковой передачи текста в речь (TTS). Разработанная внутренняя, технология обеспечивает разговоры в реальном времени, повышает опыт работы с клиентами посредством естественных взаимодействий и низкой задержки и усиливает сквозную беседную платформу ИИ компании с улучшенной аналитикой, обнаружением языка и настраиваемыми настройками автоматизации.
В июне 2024 года, Philips Speech by Shight Resecking Solutions сотрудничала с Sembly AI, чтобы запустить три новых аудиобитчика, интегрированных с технологией искусственного интеллекта. Устройства предлагают автоматические транскрипции, резюме, списки действий и понимание, в то время как Sembly AI добавляет разделение динамиков, примечания к собранию и функции повышения производительности.
Часто задаваемые вопросы
Каков ожидаемый CAGR для рынка распознавания речи и голоса в течение прогнозируемого периода?
Насколько велика была индустрия в 2024 году?
Каковы основные факторы, способствующие рынку?
Кто является ключевыми игроками на рынке?
Какой регион должен быть самым быстрорастущим на рынке в течение прогнозируемого периода?
Предполагается, что какой сегмент будет иметь самую большую долю рынка в 2032 году?
Автор
Верша имеет более чем 15-летний опыт управления консалтинговыми заданиями в различных отраслях, включая продукты питания и напитки, потребительские товары, ИКТ, аэрокосмическую промышленность и другие. Ее междисциплинарный опыт и способность к адаптации делают ее универсальным и надежным профессионалом. Обладая острыми аналитическими способностями и любопытным мышлением, Верша преуспевает в преобразовании сложных данных в практические идеи. Она имеет успешный опыт определения динамики рынка, выявления тенденций и предоставления индивидуальных решений для удовлетворения потребностей клиентов. Будучи опытным лидером, Верша успешно обучал исследовательские группы и точно руководил проектами, обеспечивая высококачественные результаты. Ее подход к сотрудничеству и стратегическое видение позволяют ей превращать проблемы в возможности и последовательно добиваться впечатляющих результатов. Анализируя рынки, привлекая заинтересованные стороны или разрабатывая стратегии, Верша опирается на свой глубокий опыт и отраслевые знания для стимулирования инноваций и достижения измеримой ценности.
Имея более десяти лет опыта руководства исследованиями на глобальных рынках, Ганапати обладает острым суждением, стратегической ясностью и глубокой отраслевой экспертизой. Известный своей точностью и непоколебимой приверженностью качеству, он направляет команды и клиентов с инсайтами, которые постоянно обеспечивают значимые бизнес-результаты.


 Рынок распознавания речи и голоса
Рынок распознавания речи и голоса